目次
はじめに
理想と現実
下準備
使ってみる
どのような文章が Neutral と判断されたか
今回行ってみて
最後に
はじめに
昨今、著名人への誹謗中傷のNewsが目立ちます。
それらを見て、誹謗中傷のような否定的なコメントでなくて、肯定的なコメントに目を向けられる仕組みを作れないかと考え始めたことが本記事のきっかけです。
今回主に使用するのはAmazon ComprehendというAWSのサービスです。
Amazon Comprehendとは機械学習を使用してテキストファイルなどを分析し、感情等の情報を抽出してくれる自然言語処理サービスです。
ではまず構成を考えていきます。
※18分もかからず3分で読めますのでブラウザバックせず最後までお付き合いいただけますと私は喜びます!笑
理想と現実
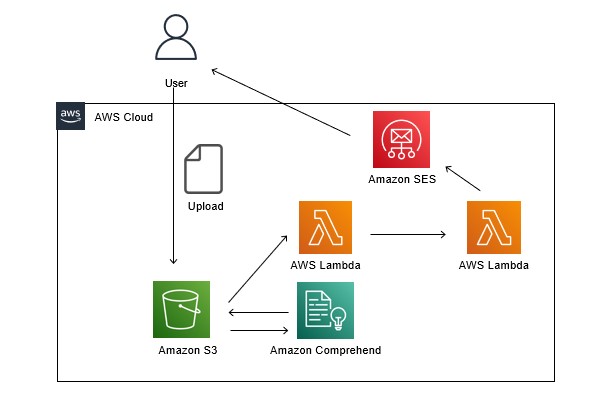
今回、AWSで下記構成をざっくり考えていました。
目的:肯定的なコメントに目を向けさせる
方法:
1.他者から自分へのコメントデータをAmazon Comprehendにて感情分析。
2.感情分析した結果がAmazon S3に出力される。その結果からPositiveと判定した言葉を抽出し、そのデータをメール添付し、指定したメールアドレスに送付 (Lambda , Amazon SES )
構成:(※未検証)
今回分析用データにはInstagramのデータを使用します。
しかし、Instagramでは、他者から自分の投稿へのコメントデータは出力できないことに気づきました。一方で、自分が他人の投稿にコメントしたデータはあるようです。
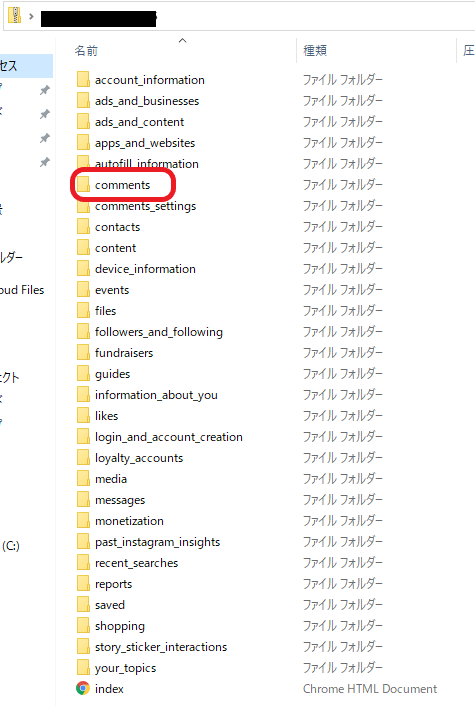
下記がInstagramから出力したデータです。htmlかjson形式でダウンロード可能です。
commetフォルダを開くと、post_comment.htmlが入っています。
開いてみると、いつ(UTC?)、どのユーザーに、どんなコメントをしたか、がわかります。
アカウント名_出力日/comments/post_comment.html
データ対象者が変わるので前提が変わってしまいました。
そのため目的の再設定と方法、構成を変更しました。
目的:自身のコメント(発言)を客観視し、省みる
方法:自分→他者へのコメントデータをAmazon Comprehendで感情分析する。
出力結果をAmazon QuickSightで可視化する。
※Amazon QuickSight
AWSのBIツール。 S3等AWSサービス上にあるデータやアップロードしたデータを分析・可視化できます。
構成:
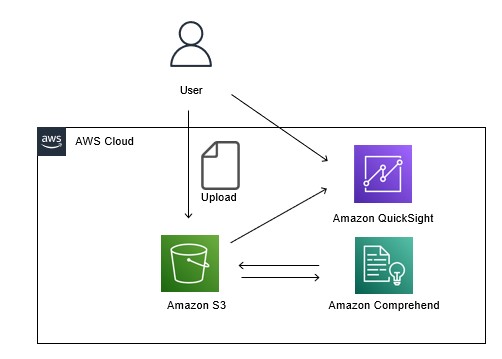
下準備
下記をあらかじめ準備しておきます。
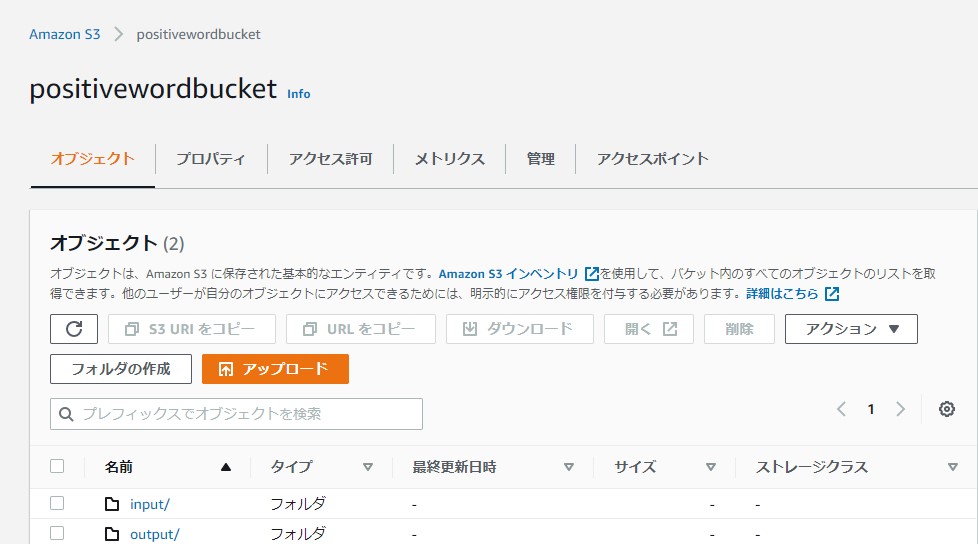
・Amazon S3にて検証用バケット(positivewordbucket )を作成し、バケット配下に下記2つのフォルダを作成。
分析用データを格納する「input」フォルダ
分析結果を出力する「output」フォルダ
・ 分析用データを「input」フォルダにアップロードしておく。
Instagaramデータでの注意点
※出力&再出力に時間を要する
取得に最大48時間要します。また、休日を挟むと取得できるのは休日明けとなるようで、更に時間がかかります。
そして、1度出力すると、4日空けなければ再出力できません。
htmlファイルを出力後、jsonファイルも出力しようとすると、上記に引っかかってしまったので、今回はhtmlファイルを加工し、自分でデータを作りました。(json形式)
//加工した分析用データ
[
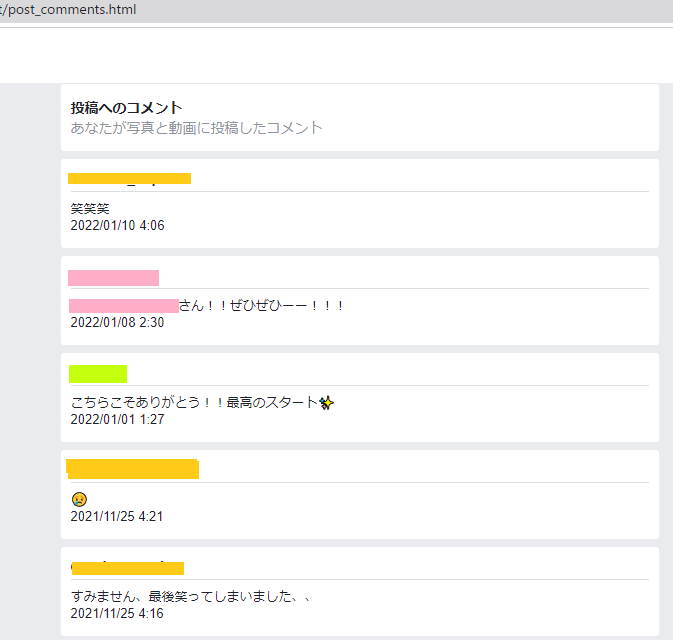
{"text":"笑笑笑"},
{"text":"user3さん!!ぜひぜひーー!!!"},
{"text":"こちらこそありがとう!!最高のスタート!"},
{"text":"すみません、最後笑ってしまいました、、"},
以下略
Amazon Comprehendでの注意点
※分析ファイルサイズ上限と文字コードに注意
サイズ上限:5,000 バイト
上限超過すると分析結果にエラーが出力されます。
ファイルの文字コード:UTF-8
参考URL: ガイドラインとクォータ
使ってみる
1.ジョブを作成する
AWSマネジメントコンソールログイン > Amazon Comprehendを検索。
日本語の感情分析対応はしていますが、設定画面は英語です。※2022/03時点
左サイドバーにある「Analysis jobs」 を選択し、右中央の「Create job」をクリックしてください。
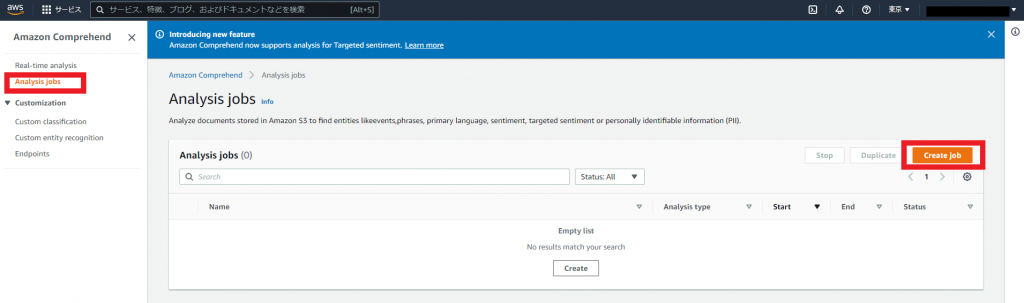
2.解析ジョブの設定画面
ジョブの名前 : 好きな名前をつけます(ここではreview-sentiment-analysis とします)
Analysis type : Sentiment (感情)
Language :Japanese
※Landuageは最初は表示されていませんが Analysis typeを選択すると その下にでてきます。
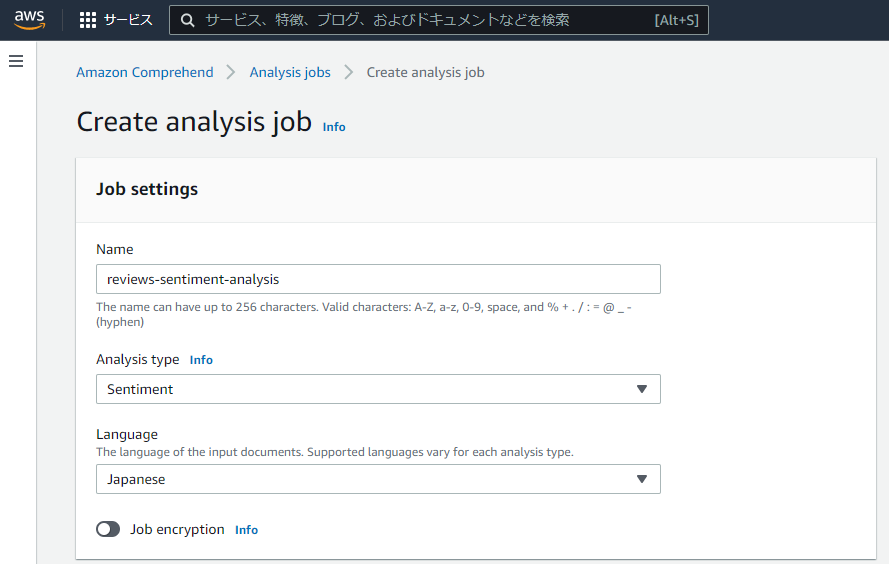
3.分析用データの指定と出力結果の格納場所を指定する
Input data
・My document を選択後、 Browse S3をクリックするとバケット選択画面が出てくるのでファイルが格納されているバケットを選択し、分析するファイル名を選択します。(もしくはS3 のフォルダURLを張り付けます)
Input format
・One document per line 1行ごとに1つの文章とみなして1つ1つ分析してくれます。今回はこちらを選択します。
※One document per file を選択すると、1ファイルを1つの文章とみなし、分析されます。
Output date
・input と同様に、Browse S3をクリックし分析結果の出力先フォルダを選びます。
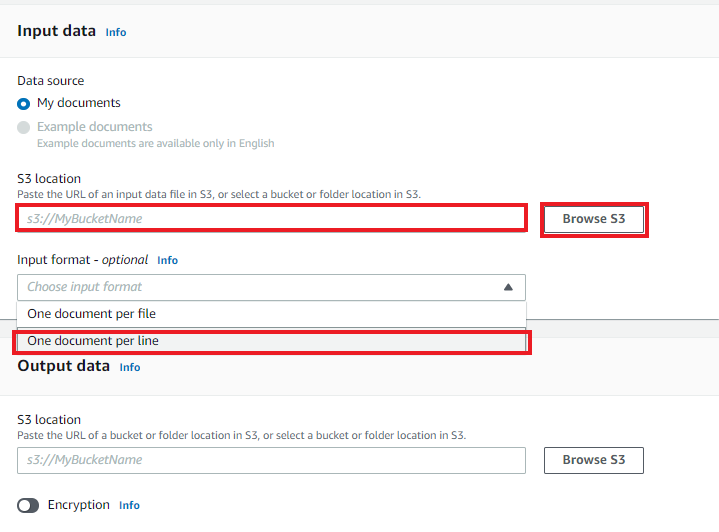
4. Access permissions パーミッション設定
Amazon Comprehend がS3へデータをアクセスできるよう設定します。
Create an IAM role > Input and Output S3 buckets を選択し、
Name suffix > AmazonComprehendServiceRole ※ロール名
※AWSおさらい
AWSサービス間連携するには必ずロール(権限)が必要となります。
参考:用語と概念
右下の「Create job」をクリックします。 すると分析が開始されます。
すると Analysis jobsの一覧画面に戻るので、完了まで数分待ちます。
完了すると、右端にあるStatusが In progress → completeに代わるのでjobのNameをクリックします。
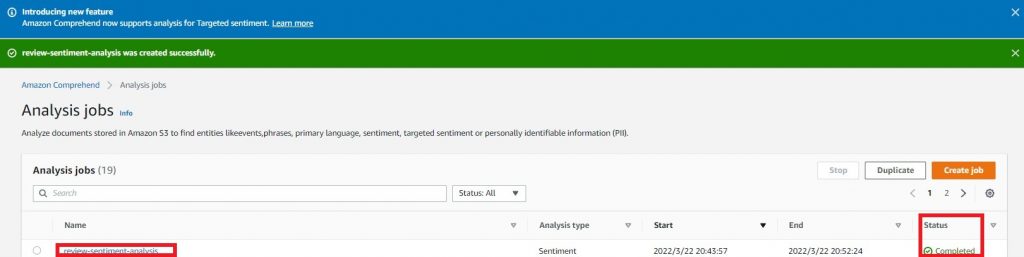
【Output】の欄に出力したデータのS3 URLが記載されています。そちらをクリックし、データをダウンロード。
gz形式でダウンロードされるのでお手持ちのzip解凍ソフトで解凍します。
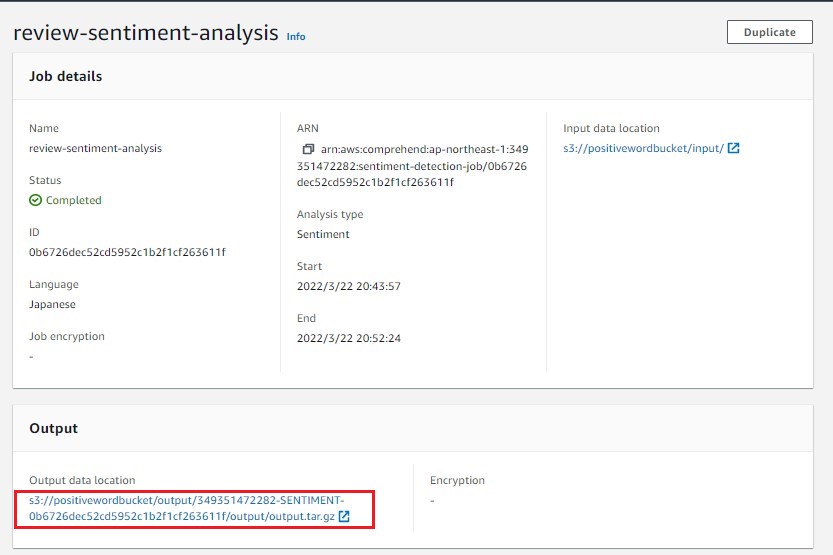
分析結果をエディタで開いてみると、
ファイル、ファイル名、何行目か、感情分析結果(感情スコアで一番高かったもの)、各感情スコア(Mixed、Negative、Neutral、Positive)ごとに区切られたデータが出力されています。
{"File": "itport.json", "Line": 5, "Sentiment": "POSITIVE", "SentimentScore": {"Mixed": 0.0018087667413055897, "Negative": 0.0004777743015438318, "Neutral": 0.007918132469058037, "Positive": 0.9897953867912292}}
{"File": "itport.json", "Line": 20, "Sentiment": "POSITIVE", "SentimentScore": {"Mixed": 0.12779146432876587, "Negative": 0.14545804262161255, "Neutral": 0.05011679232120514, "Positive": 0.6766336560249329}}
{"File": "itport.json", "Line": 19, "Sentiment": "NEUTRAL", "SentimentScore": {"Mixed": 0.0003464518813416362, "Negative": 0.07718004286289215, "Neutral": 0.8824456930160522, "Positive": 0.04002784192562103}}
{"File": "itport.json", "Line": 18, "Sentiment": "POSITIVE", "SentimentScore": {"Mixed": 0.006245748605579138, "Negative": 0.006083638872951269, "Neutral": 0.19375722110271454, "Positive": 0.7939133048057556}}
{"File": "itport.json", "Line": 6, "Sentiment": "NEUTRAL", "SentimentScore": {"Mixed": 0.0001197314340970479, "Negative": 0.11390578746795654, "Neutral": 0.8220511674880981, "Positive": 0.06392333656549454}}
{"File": "itport.json", "Line": 7, "Sentiment": "POSITIVE", "SentimentScore": {"Mixed": 8.480736869387329e-05, "Negative": 0.01553039625287056, "Neutral": 0.30140742659568787, "Positive": 0.6829773187637329}}
{"File": "itport.json", "Line": 8, "Sentiment": "POSITIVE", "SentimentScore": {"Mixed": 1.2530498679552693e-05, "Negative": 0.0008051947224885225, "Neutral": 0.01031503826379776, "Positive": 0.9888672232627869}}
{"File": "itport.json", "Line": 17, "Sentiment": "POSITIVE", "SentimentScore": {"Mixed": 7.583337719552219e-05, "Negative": 0.0007654883665964007, "Neutral": 0.08088481426239014, "Positive": 0.9182738661766052}}
{"File": "itport.json", "Line": 1, "Sentiment": "NEUTRAL", "SentimentScore": {"Mixed": 3.3626747608650476e-05, "Negative": 0.00070447928737849, "Neutral": 0.980109691619873, "Positive": 0.019152116030454636}}
{"File": "itport.json", "Line": 2, "Sentiment": "NEUTRAL", "SentimentScore": {"Mixed": 0.00010978984937537462, "Negative": 0.0007362283067777753, "Neutral": 0.9087120294570923, "Positive": 0.09044187515974045}}
{"File": "itport.json", "Line": 3, "Sentiment": "POSITIVE", "SentimentScore": {"Mixed": 1.9933080693590455e-05, "Negative": 5.585489634540863e-05, "Neutral": 0.0019222585251554847, "Positive": 0.9980019927024841}}
{"File": "itport.json", "Line": 4, "Sentiment": "NEUTRAL", "SentimentScore": {"Mixed": 2.1359172023949213e-05, "Negative": 0.015238307416439056, "Neutral": 0.8998493552207947, "Positive": 0.0848909467458725}}
{"File": "itport.json", "Line": 9, "Sentiment": "NEUTRAL", "SentimentScore": {"Mixed": 5.3778087021782994e-05, "Negative": 0.002293737605214119, "Neutral": 0.5788528323173523, "Positive": 0.41879963874816895}}
{"File": "itport.json", "Line": 10, "Sentiment": "POSITIVE", "SentimentScore": {"Mixed": 0.0005071907653473318, "Negative": 0.003279498079791665, "Neutral": 0.33202025294303894, "Positive": 0.6641931533813477}}
{"File": "itport.json", "Line": 11, "Sentiment": "POSITIVE", "SentimentScore": {"Mixed": 0.0006057260907255113, "Negative": 0.003877989249303937, "Neutral": 0.31974485516548157, "Positive": 0.6757714748382568}}
{"File": "itport.json", "Line": 12, "Sentiment": "POSITIVE", "SentimentScore": {"Mixed": 0.0001589574821991846, "Negative": 0.0005781771615147591, "Neutral": 0.054736435413360596, "Positive": 0.9445263743400574}}
{"File": "itport.json", "Line": 13, "Sentiment": "NEUTRAL", "SentimentScore": {"Mixed": 9.035522089106962e-05, "Negative": 0.010315156541764736, "Neutral": 0.9519026875495911, "Positive": 0.03769190236926079}}
{"File": "itport.json", "Line": 14, "Sentiment": "POSITIVE", "SentimentScore": {"Mixed": 2.398918877588585e-05, "Negative": 0.0006118506425991654, "Neutral": 0.022029953077435493, "Positive": 0.977334201335907}}
{"File": "itport.json", "Line": 16, "Sentiment": "POSITIVE", "SentimentScore": {"Mixed": 0.00018084494513459504, "Negative": 0.02024434693157673, "Neutral": 0.3516538143157959, "Positive": 0.6279210448265076}}
{"File": "itport.json", "Line": 21, "Sentiment": "POSITIVE", "SentimentScore": {"Mixed": 0.0017340347403660417, "Negative": 0.14323210716247559, "Neutral": 0.15760460495948792, "Positive": 0.6974292397499084}}
{"File": "itport.json", "Line": 22, "Sentiment": "NEUTRAL", "SentimentScore": {"Mixed": 4.854716462432407e-05, "Negative": 0.0008625781047157943, "Neutral": 0.9477819800376892, "Positive": 0.05130685865879059}}
{"File": "itport.json", "Line": 0, "Sentiment": "NEUTRAL", "SentimentScore": {"Mixed": 0.05278225243091583, "Negative": 0.030287476256489754, "Neutral": 0.9018653035163879, "Positive": 0.015064935199916363}}
{"File": "itport.json", "Line": 15, "Sentiment": "NEUTRAL", "SentimentScore": {"Mixed": 0.0002573688980191946, "Negative": 0.001819703378714621, "Neutral": 0.9621109962463379, "Positive": 0.03581199049949646}}
{"File": "itport.json", "Line": 23, "Sentiment": "NEUTRAL", "SentimentScore": {"Mixed": 0.051544614136219025, "Negative": 0.016457311809062958, "Neutral": 0.9150579571723938, "Positive": 0.01694006286561489}}
次にAmazon QuickSightで可視化しました。
今回作業手順は割愛しますが、非常に興味深いサービスだったのでまた別記事で書きたいなと思います。
ちなみに6割 Positve 4割 Neutralという結果でした。
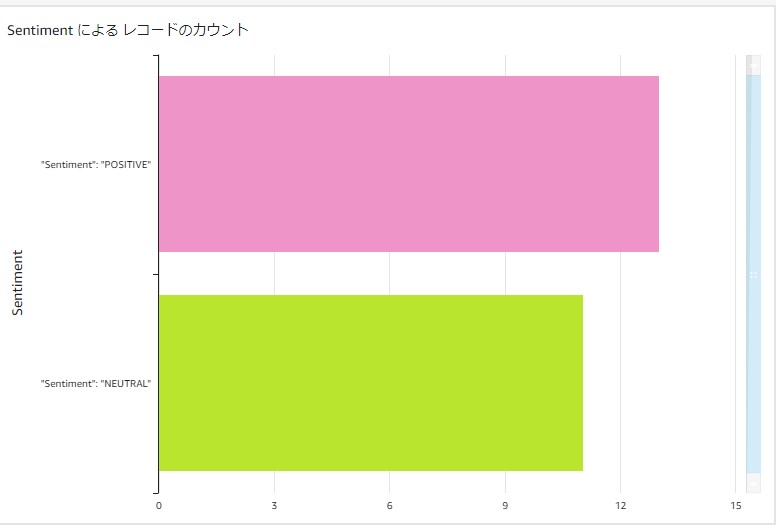
どのような文章が Neutral と判断されたか
Neutral は中立(どちらでもない)のですが、どのような文章が判断されたか気になるので見てみます。
ちょっと恥ずかしいのですが、わかりやすさ重視して分析データの内容をあげます。
Neutralと判断された行数:0 , 1 , 2 , 4 , 6 , 9 , 13 , 15 , 19 , 22 , 23
0 [
1 {"text":"笑笑笑"},
2 {"text":"user3さん!!ぜひぜひーー!!!"},
4 {"text":"すみません、最後笑ってしまいました、、"},
6 {"text":"@user1見ずに焼いてしまいました笑 塩鮭だったようです(めちゃしょっぱかった)"},
9 {"text":"すごい神秘的~!!!"},
13 {"text":"めちゃめちゃ"},
15 {"text":"感動"},
19 {"text":"@user1 なんか目覚ましに絶対的な信頼を置いてしまい、甘えて起きれなくなりました笑 朝活手帳は事前に朝起きたらなにやろうか計画記入して、その日にまたできたかフィードバックします!計画の時点で、すべきこと認識できて起きやすかったです!! もしよろしければ調べてみてください~!"},
22 {"text":"天才"},
23 ]
Positive判定された10行目と11行目が「感動しました」だったので、 15行目の「感動」がNeutralになったのはなぜなのか不思議です。
10 {"text":"感動しました!!"},
11 {"text":"感動しました!!!!"},
4行目は「すみません」と謝罪の言葉があったので「笑った」という単語があってもNeutralになったのではと推測。
19行目は光目覚ましを使った感想と、朝活手帳について先輩にお伝えしたものなのですが、光目覚ましに対しては「わたしにはあまり合わなかった」・朝活手帳は「良かった」という意で書いたので、Neutralになったのではと思います。 ただ、「Mixed」との違いや「Mixed」の値が0.0003と一番低いのが気になりました。
ここはもう少し調べて勉強したいと思います。
今回行ってみて
感想を大きく2つにわけて記載します。
1.Amazon Comprehendを使用した感想
テキストを分析し、感情を出してくれる、というのが 単純に興味深かったです。
あとは 分析データの行内容も結果に合わせて表示されたら更にわかりやすくて良いと思いました。
改善策としては、Amazon ComprehendをLambdaから実行し、その際に少し工夫すれば行えるようです。
参考:AWS Comprehendの感情分析を使ってみた
2.SNSコメント分析はInstagramでなく 他SNS(Ex. Twitter)だと容易だと思われる。
今回Instagramのデータ取得が手動で時間を要しました。
InstagramのAPIはあるのですが、コメント管理等はビジネスアカウントでないと使えないようです。
参考 :InstagramグラフAPI
一方、こちらのAWS公式記事では、Twitterのタイムラインを感情分析しています。
TwitterはAPI連携等できるようで、こちらのほうが自動でスムーズ・スマートに行えそうだと思いました。
参考: Twitter のタイムラインで流れる話題を AWS の AI サービスで分析してみる ~前編
今回データを手動で取得し整形してから分析したりと、スマートに行えなかったですが、
私が四苦八苦する姿をみて、新しい仕組みを思いついていただけたり、何より今、誹謗中傷を受けて悩んでいる人が少しでも元気になっていただければこの記事を書いた甲斐があったなと感じます。
最後に
「他者→自分へのコメント」でなく「自分→他者へのコメント」を感情分析するという想定外のこととなりましたが、様々気づきも得られた他、触ったことのないAWSサービスを2つも使うことができ、充実した時間となりました。
今回の作業を通して、
誹謗中傷という大きい問題を解決しようと思うなら、見知らぬ他人の言動を指摘する前に、まず自分自身がいつも肯定的な言葉を話しているのか振り返り、自分から変わることから始めようと思えました。
また、私がSNSでやり取りするのは親しい人だけなので、今回肯定的な結果がでて当たり前だと思います。
なので、日々どんな時でも肯定的な言葉を意識したいと思います!
読んでくださりありがとうございました。