
目次
はじめに
使用するサービス
今回やってみたいこと
気になること
やってみました
結果
最後に
はじめに
あっという間に1年の半分が過ぎ、後半戦に入りました。毎年年末にいつも考えることがあるのですが、それは「自分が1年間、時間を『何に』使ってきたか」です。なので、仕事外の時間何をしていたか、スケジュール帳に書いて残していくようにしているのですが、年末に振り返ったときにパッとわからないのがネックでした。しかし手で1年分を集計するわけにもいきません。スケジュールアプリによっては集計、グラフ化できるものもありますが、私はスケジュール帳に手書きで書き残していくのが好きなので、アプリは使わずに何かできないか考えていました。そこで「スケジュール帳をOCRし、データ抽出すればいいのでは」と思ったことが本記事の経緯です。
使用するサービス
今回もAWSでやっていきます。はじめて使うサービスですがAmazon Textractを使います。
下記AWS公式からの引用です。ちなみに、日本語はまだ対応していないようです(2022/07 時点)
Amazon Textract は、スキャンしたドキュメントからテキスト、手書き文字、およびデータを自動的に抽出する機械学習 (ML) サービスです。
引用元:Amazon Textract https://aws.amazon.com/jp/textract/
今回やってみたいこと
日々の記録はスケジュール帳の月間ブロックに記入しているので、下記のような手順で挑戦したいと思います。
- スケジュール帳の月間ブロックを写真撮る
- その写真をOCRにかけ、データを抽出する
また、AmazonTextractは日本語に対応していないので、適当な英語で検証用に記入し、用意しました。
| 通勤時間(行き、帰り) | CM,CE(Commute time /Morning or Evening) |
| 昼休み | L (Lunch time) |
| 仕事後 | AW(After work) |
| 休日(午前、午後) | AM1,AM2,PM1,PM2 |
| おこなったこと | training,reading,cafe,zoom,study…等々 |
精度検証もかねて雑に記入してみました (studyが書きやすく結構多く書いてしまいました)

気になること
AmazonTextractの前提知識なしで気になっていることは
- シャーペン(HB)の文字もちゃんと読み取ってくれるのか
最近ボールペンでなく、HBのシャーペンで書くようになってきたので、薄い字でも読み取れるか気になっています。 - デフォルト仕様だけで データ出力できるのか
Lambdaや他AWSサービスを準備せずともできるのか気になっています。 - 精度
手書きの文字をどこまで正確に読み取れるかはやはり一番気になります。今回準備するなかで、PM2:zoomと書いた欄があったのですが、その時に「2」と「Z」をしっかり区別できるのか等も気になりました。
やってみました
AWS マネジメントコンソールにログイン>Amazon Textractを選択すると東京リージョンが使用できないためリージョンを聞かれます。今回はソウルリージョンを選択します。
その後スタート画面に入ります。
左サイドメニューの デモ>文書を分析する を押下します。
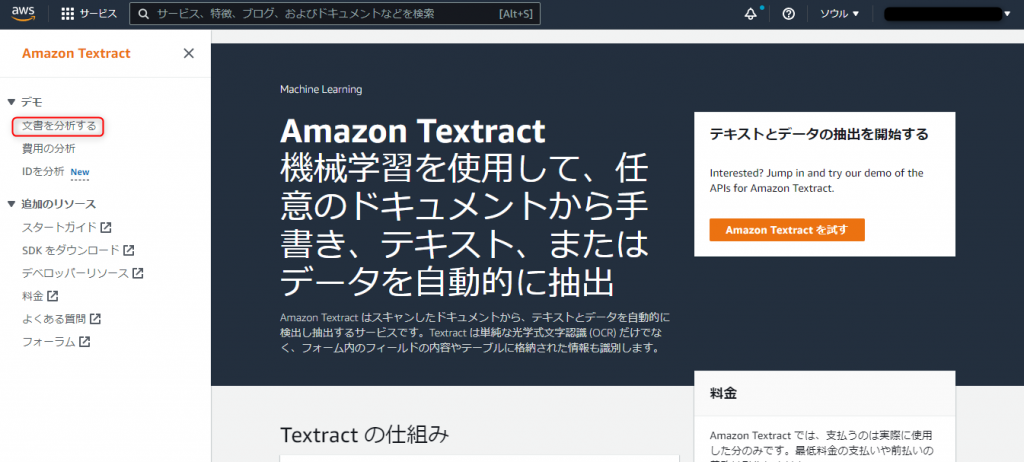
ダミーデータを読み取った状態が表示されており、読み取った後の様子がなんとなくわかります。
下部の「ドキュメントをアップロード」から今回用意したダミーデータ.pngをアップします。
※その下の注意書きでドキュメントの制限が記載されています。
ドキュメントは 11 ページ未満、5 MB 未満で、JPEG、PNG または PDF のいずれかの形式で、とのことです。
その後データ出力形式を尋ねられるため、フォームor テーブル or クエリ いずれかを選択し、設定を適用を押下します。今回は一応表形式になるのかと思い、テーブルを選択してみました。
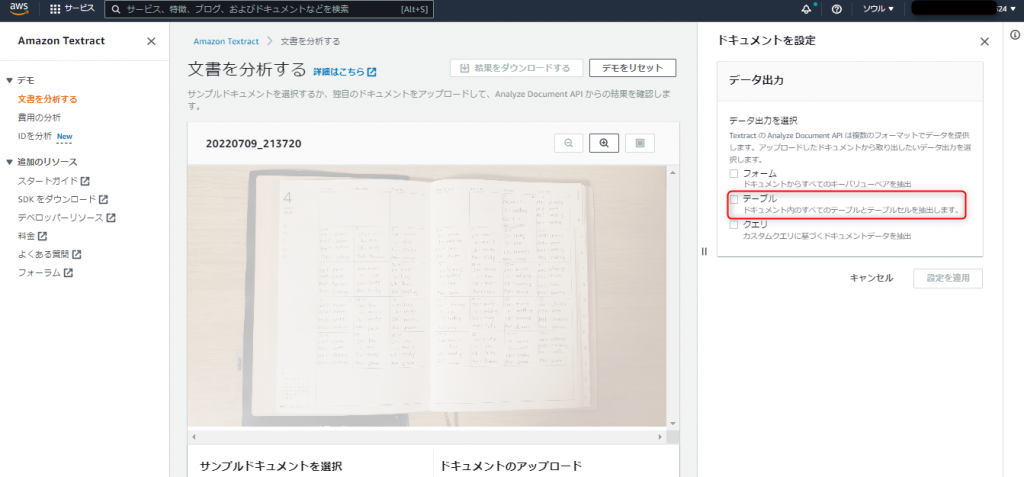
するとOCRされ、手書き文字がテキストデータとして抽出されます。
今回シャーペンで書いた文字も問題なく抽出されているのが確認できました。
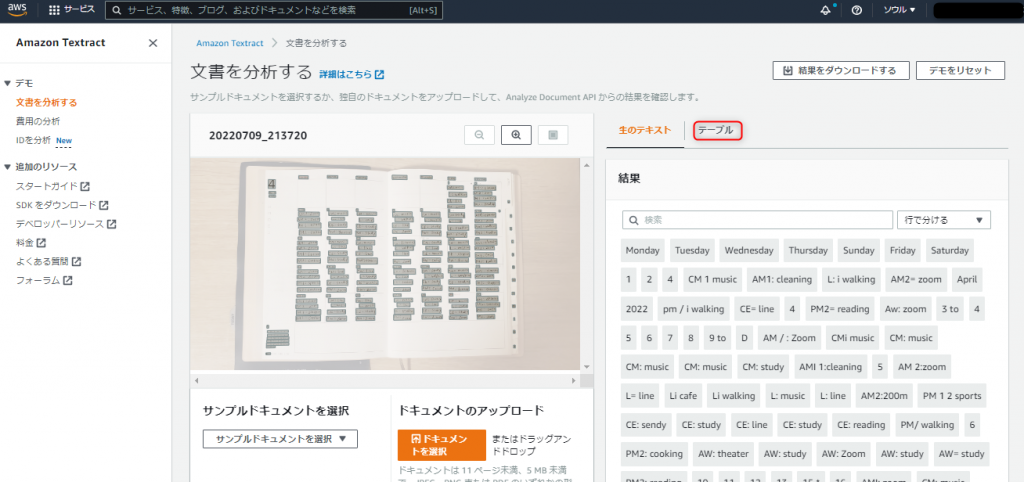
テーブルタブを押下すると表形式でそのまま読み取られていることがわかります。
スケジュール帳ほぼそのままのレイアウトで、ここが個人的に感動しました!!!
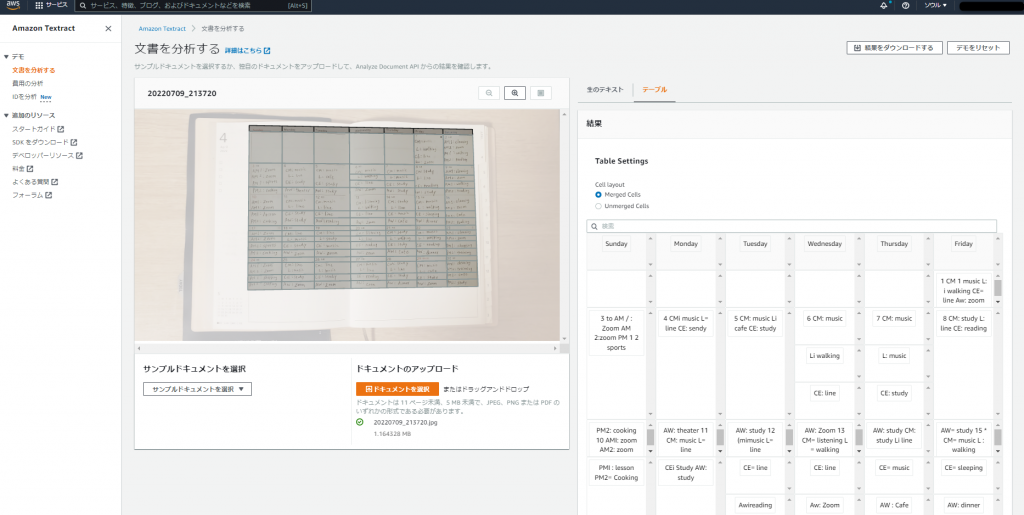
デフォルトではCell layout:Merge cellが選択されていますが Unmerged cellを選択すると更に細かくわけて出力されます。 ただ、日付のブロック内は同じように記載していたのでなぜ行ごとに分けられているものとそうでないものがあるのかはわかりません…判断基準がとても気になります。
右上の【結果をダウンロードする】を押下するとzip形式でデータがダウンロードされます。
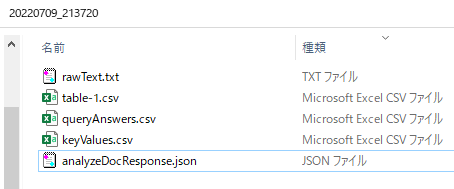
5つほどファイルがダウンロードできます。table-1.csvを開いてみると、表形式で出力されています。
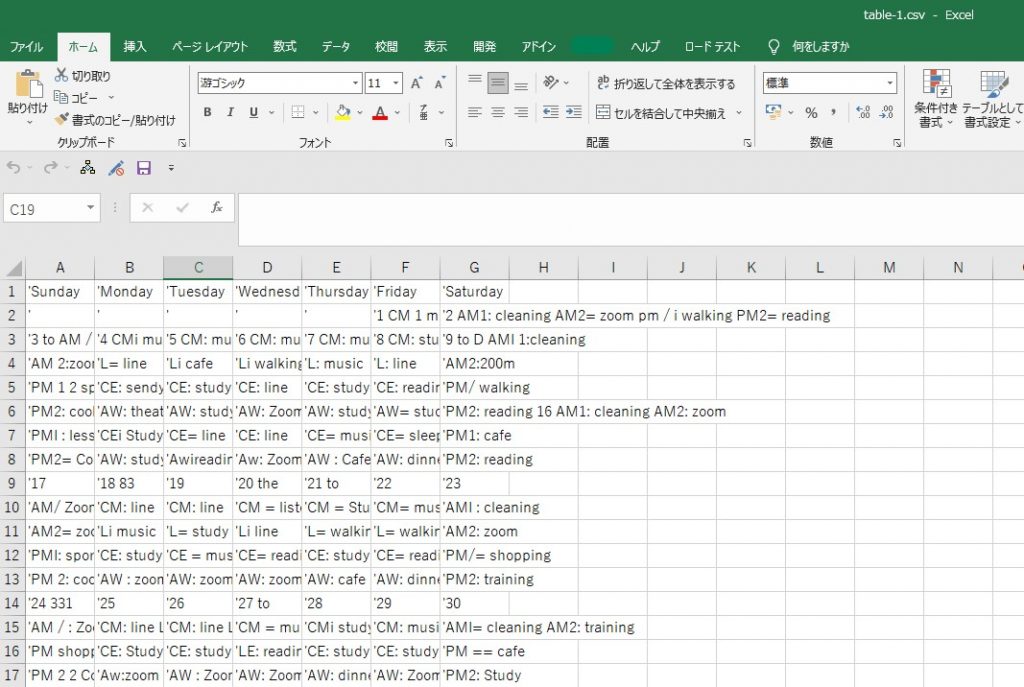
rawText.txtは抽出されたそのままのデータです。
こちらで精度をざっと確認すると、
:→=
:→i
AM1→AM/ や AMl
仏滅 →the
といったいくつか誤ったものはありましたが、:や1の誤検知は確かに間違えそうなものだなということと、
【仏滅】等の漢字は日本語非対応の為、しょうがないとすると、汚い文字にもかかわらず、ほぼ正確に抽出されていることが確認されました。zoom も2oomと抽出されたものはひとつもなく、精度の高さを感じました。
Monday
Tuesday
Wednesday
Thursday
Sunday
Friday
Saturday
1
2
4
CM 1 music
AM1: cleaning
L: i walking
AM2= zoom
April
2022
pm / i walking
CE= line
4
PM2= reading
Aw: zoom
3 to
4
5
6
7
8
9 to
D
AM / : Zoom
CMi music
CM: music
CM: music
CM: music
CM: study
AMI 1:cleaning
5
AM 2:zoom
L= line
Li cafe
Li walking
L: music
L: line
AM2:200m
PM 1 2 sports
CE: sendy
CE: study
CE: line
CE: study
CE: reading
PM/ walking
6
PM2: cooking
AW: theater
AW: study
AW: Zoom
AW: study
AW= study
PM2: reading
10
11
12
13
15 *
16
AMI: zoom
CM: music
(mimusic
CM= listening
CM: study
CM= music
AM1: cleaning
7
AM2: zoom
L= line
L= line
L = walking
Li line
L : walking
AM2: zoom
PMI : lesson
CEi Study
CE= line
CE: line
CE= music
CE= sleeping
PM1: cafe
8
PM2= Cooking
AW: study
Awireading
Aw: Zoom
AW : Cafe
AW: dinner
PM2: reading
17
18 83
19
20 the
21 to
22
23
9
AM/ Zoom
CM: line
CM: line
CM = listening
CM = Study
CM= music
AMI : cleaning
AM2= zoom
Li music
L= study
Li line
L= walking
L= walking
AM2: zoom
PMI: sports
CE: study
CE = music
CE= reading
CE: study
CE= reading
10
PM/= shopping
PM 2: cooking
AW : zoom
AW: zoom
AW: zoom
AW: cafe
AW: dinner
PM2: training
24 331
25
26
27 to
28
29
30
11
AM / : Zoom
CM: line
CM: line
CM = music
CMi study
CM: music
AMI= cleaning
AM 2 : Zoom
Limusic
Le music
L: line
L= line
Li cafe
AM2: training
12
PM shopping
CE: Study
CE: study
LE: reading
CE: study
CE: study
PM == cafe
PM 2 2 Cooking
Aw:zoom
AW : Zoom
AW: Zoom
AW: dinner
AW: Zoom
PM2: Study
1
5
S M T W T F S
1 2 3 4 5 6 7
2
8 9 10 11 12 13 14
15 16 17 18 19 20 21
22 23 24 25 26 27 28
29 30 31
3
. WA
結果
結果
1 .シャーペン(HB)の文字もちゃんと読み取ってくれるのか →できる
2 . デフォルト仕様だけで データ出力できるのか →できる
3 . 精度 →非常に高い(英語にて 8,9割正確に抽出可能)
初めて使いましたが精度、そして、テーブル形式でそのまま出力されたこと、小さい事のようですが私はいたく感動しました。テーブル形式以外にも他の出力形式も選択でき、(クエリ・フォーム)柔軟に様々な用途に使えそうです。日本語対応されることを楽しみにしたいと思います!
最後に
今回の記事を書く中で、自分が年末年始に決心したこと等を思い出すいい機会となりました。1秒1秒貴重に使っているか、そのように心がけているか?というとかなりだらけているなと感じます。2022年の後半戦、年始に決心したことを再度思い出して1秒1秒貴重に使い未練なく2023年を迎えたいと思います。
※前回の記事もAWS機械学習サービスについて書かせていただきました。
私のお気に入り記事ですのでこちらも是非ご覧になってください!





