
目次
はじめに
前回までは顔検出や物体検出を静止画や動画で行ってみました。
最終回となる今回は画像ではなく文字を検出・認識するOCRを行ってみたいと思います。
これで画像認識、文字認識と機械学習等の結果でよく利用されるアウトプットを行ってみることができます。
OCRとは
OCRとは、 Optical Character Recognition (またはReader)の略で光学文字認識のことを言います。
具体的には画像中の文字を検出し、文字データに変換する技術です。
OCRを利用することで、入力業務や文書管理といった業務を効率よく行えたりします。
当ブログでも別テーマにてOCRを扱った記事を掲載していますので、下記のリンクをクリックしてみてください。

使用するライブラリ
Tesseract OCR
Google(元々はHP)が開発したオープンソースのOCRエンジンです。
日本語だけでなく100以上の言語が対応しており、学習をさせることによって用意されていない言語にも対応が可能となります。
Tesseractのインストールは、まずhttps://github.com/UB-Mannheim/tesseract/wikiに記載されているURLから、32bitまたは64bitのインストーラをダウンロードします。
今回は、執筆時の最新版のTesseract-OCR V5.0.0-alpha.20191010を使用します。
インストールするか選択できます。
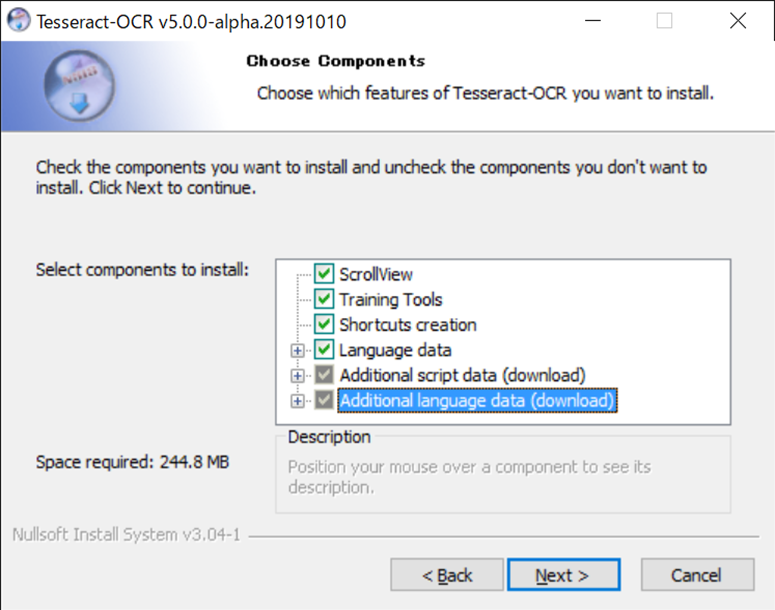
日本語を選択します。
両方入れておきます。
インターネットに接続する必要があります。
インストール後、下記のパスを環境変数に登録します。
- Pathに「C:\Program Files\Tesseract-OCR」を追加する。
- 環境変数項目としてTESSDATA_PREFIXを作成して、「C:\Program Files\Tesseract-OCR\tessdata」を追加する
※上記のパスはTesseractのインストール先フォルダとなります。今回は64bit版Tesseractのデフォルトのインストール先となっています。32bit版の場合はインストール先フォルダが異なるため、注意してください。
学習データの入手

上記のリンクから学習データを入手します。
Ver.4.0.0以降は、以下のSuffixが付与されている学習データも用意されています。
- _fast:速度重視
- _best:精度重視
- Suffixなし:通常
PyOCR
Python用のOCRツールラッパーライブラリです。
PythonからTesseract等のOCRツールを利用出来るようにします。
pip install pyocr
Tesseract,PyOCRを用いたOCR
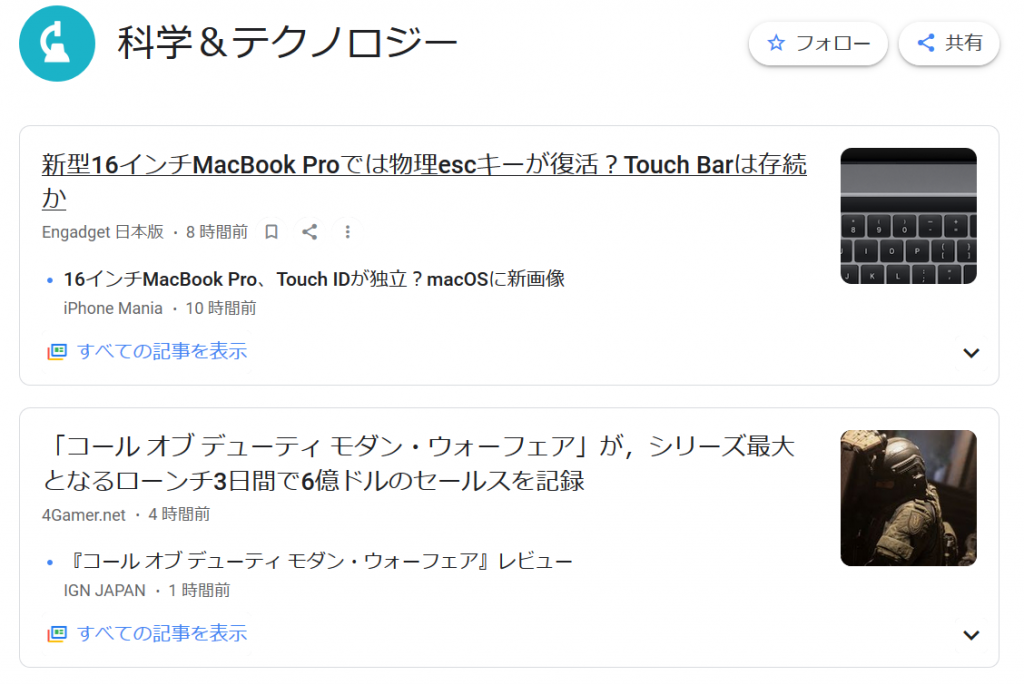
今回は以下の画像から文字を抽出・認識させてみたいと思います。
import pyocr
import pyocr.builders
import cv2
from PIL import Image
import sys
#利用可能なOCRツールを取得
tools = pyocr.get_available_tools()
if len(tools) == 0:
print("OCRツールが見つかりませんでした。")
sys.exit(1)
#利用可能なOCRツールはtesseractしか導入していないため、0番目のツールを利用
tool = tools[0]
#画像から文字列を取得
res = tool.image_to_string(Image.open("画像ファイルのパス"),lang="jpn",builder=pyocr.builders.WordBoxBuilder(tesseract_layout=6))
#取得した文字列を表示
print(res)
#以下は画像のどの部分を検出し、どう認識したかを分析
out = cv2.imread("画像ファイルのパス")
for d in res:
print(d.content) #どの文字として認識したか
print(d.position) #どの位置を検出したか
cv2.rectangle(out, d.position[0], d.position[1], (0, 0, 255), 2) #検出した箇所を赤枠で囲む
#検出結果の画像を表示
cv2.imshow("img",out)
cv2.waitKey(0)
cv2.destroyAllWindows()
ここで、検出するパターンとしてWordBoxを利用しています。
WordBox以外にも下記のパターンがあります。
TextBuilder 文字列を認識
WordBoxBuilder 単語単位で文字認識 + BoundingBox
LineBoxBuilder 行単位で文字認識 + BoundingBox
DigitBuilder 数字 / 記号を認識
DigitLineBoxBuilder 数字 / 記号を認識 + BoundingBox
Tesseractには他言語でのデータも用意されているので、インストール時に日本語以外の言語データ、言語スクリプトをインストールし、上記コードのlang=”jpn”の部分を別言語コードを入力すると日本語以外にも対応できます。
また、認識のレイアウトパターンを以下から選択します。
これらのパターンで精度が大きく変わってきますので、読み取る画像に合わせて選択します。
0 文字角度の識別と書字系のみの認識(OSD)のみ実施(OCRは実施されない)
1 OSDを利用した自動ページセグメンテーション
2 OSDまたはOCRを利用しない自動セグメンテーション
3 OSDなしの完全自動セグメンテーション(デフォルト)
4 可変サイズの1列テキストを想定する
5 縦書きの単一のテキストブロックと想定する
6 横書きの単一のテキストブロックと想定する
7 画像を1行のテキストと想定する
8 画像を1つの単語と想定する
9 円の中に記載された1単語と想定する(①などの丸数字等)
10 画像を1文字と想定する
以上のコードでOCR処理してみると以下の結果が得られました。
0W 入学&テクノロジー フォロー <
新型16インチMacBook Proでは物理escキーが復活 ? Touch Barは存続
か
Engadget 日本版 ・8時間前 口 く : 間
・ 16インチMacBook Pro、Touch IDが独立 ? mac0Sに新画像
iPhone Mania ・10 時間前
ン
回 すべての記事を表示
「コール オブ デューティ モダン・ウォーフェア」 が, シリーズ最大
となるローンチ3日間で6億ドルのセールスを記録
4Gamernet ・4時間前
・『コール オブ デューティ モダン・ウォーフェア』レビュー
IGN JAPAN ・ 1 時間前
回 すべての記事を表示
図やマークが文字として読み取られていたり、「科学」が「入学」と誤認識されている以外はかなり高い精度で読み取れています。
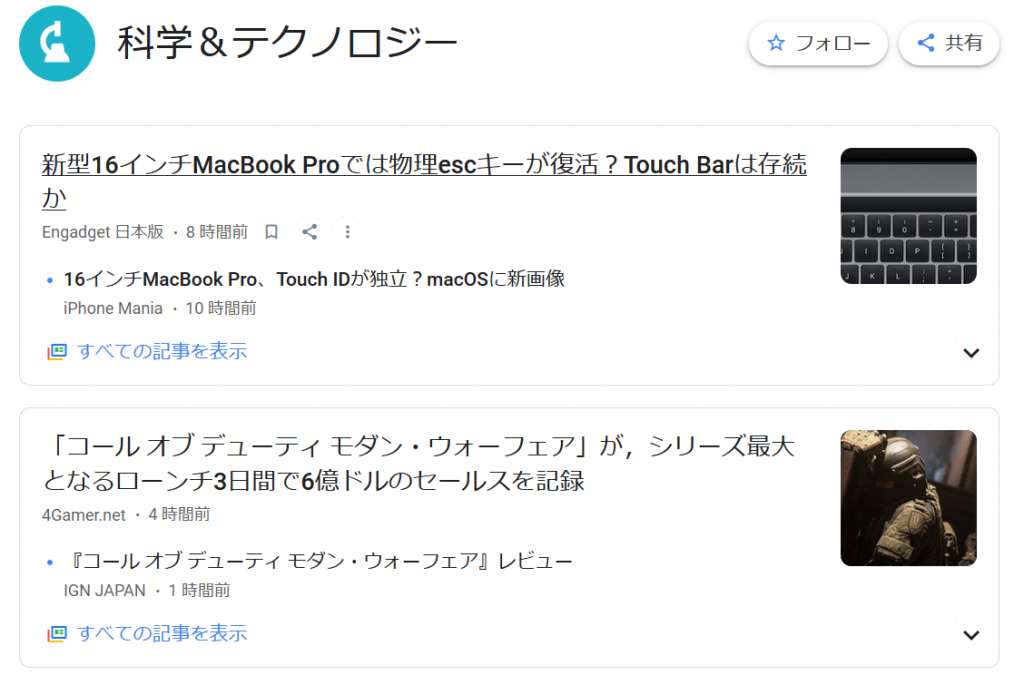
また以下の画像は、実行コードの23行目以降に記載されているTesseractの結果をOpenCVで画像のどの部分を検出しているか赤枠で示したものになります。
上記のコードを実行すると最後にWindow画面に表示されます。
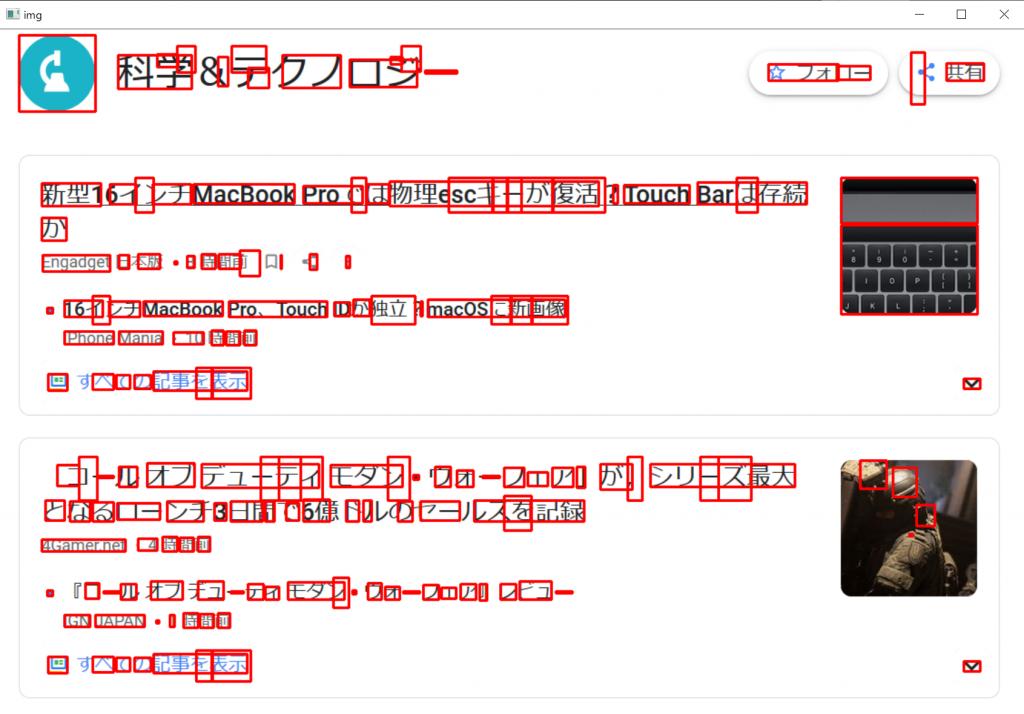
ほとんどの文字が検出対象になっており、写真の一部も検出対象になっています。キーボードの写真が「間」と変換されているのは確かに「間」に見えなくもない?!
おわりに
静止画のOCRを実施し、オープンソースのツールでもある程度の文字認識精度が得られることがわかりました。
これを応用して動画でリアルタイムに文字を認識するアプリケーションといったものも作ることができそうです。
PythonとOpenCV + αでいろいろ遊んでみましたが、機械学習が発達するなか画像や動画処理を行えるようになると、利用の幅が広がり、応用しておもしろいことが出来そうな気がします。
この連載では機械学習の結果の利用について、画像、文字認識を行ってきましたが、別のテーマにて機械学習の学習等についても書いてみたいとも思います。





