
目次
はじめに
効率化したい業務内容
使用ツール
メールから添付ファイルを自動保存
OCRでドキュメントファイルに変換
スプレッドシートへ転記
イベントトリガーを設定
最後に
はじめに
昨今多くの企業で業務効率化が推進され、従来紙でやりとりされていた業務も次々と電子データ化されています。
しかし依然として紙を使用する業務も多く、それらを自動化するための新たな技術が次々と生まれています。
今回はPDFや画像をテキストデータ化するOCR(Optical Character Recognition/Reader )技術を利用し、
業務効率化に役立つシステムを作成してみたいと思います。
効率化したい業務内容
営業の業務の例として、顧客からの押印付注文書をFAXやメールに添付された
pdfファイルでいただき、それを目視して別システムへ入力、というものがあります。
この業務に関して、次のようなシステムを作成したいと思います。
- Google Driveに対象添付ファイルを自動保存
- pdfデータをOCRを利用し文字起こし
- テキストデータをスプレッドシートへ転記
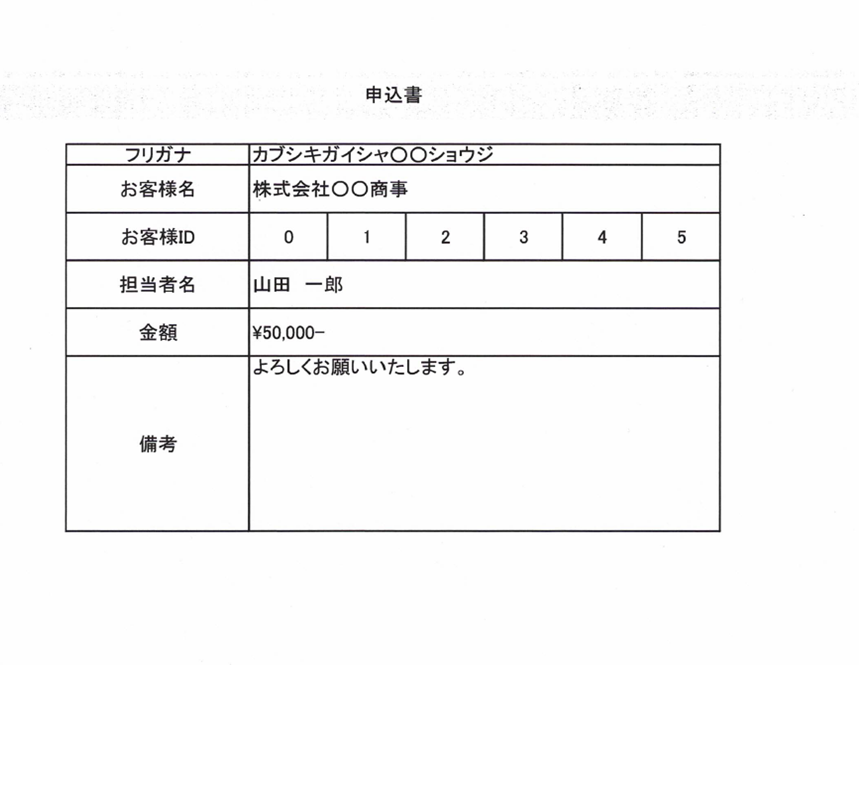
今回、以下のような申込書を用意しました。
こちらを使用して文字起こしを行います。
使用ツール
- Gmail
- Google Drive
- Google Sheets
- GAS (Google Apps Script)
GAS (Google Apps Script)とは、Googleが提供するサーバーサイドスクリプト環境です。
Googleが提供する様々なサービスとの連携が可能で、スプレッドシートやGmail、Googleドライブを用いた業務の自動化に最適です。
Googleアカウント、ブラウザ、ネットワーク環境があれば誰でも無料で始めることができます。
GASでできることや詳しい始め方は下記を参照いただければと思います。
https://developers.google.com/apps-script/overview
メールから添付ファイルを自動保存
OCR機能を利用する前に、まず受信メールから対象ファイルを検索、Google Driveへ保存します。
事前にマイドライブに「testOCR」というフォルダを準備しています。
このフォルダにpdfファイルを保存していきます。
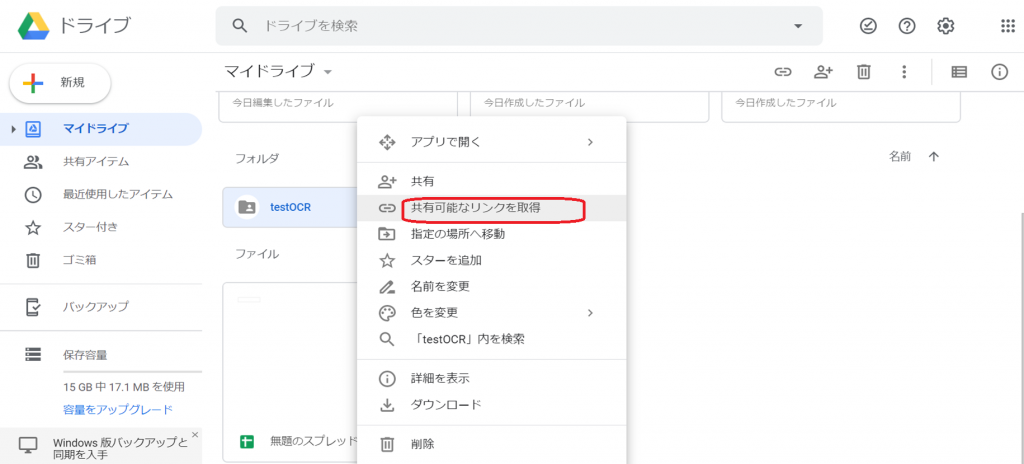
またフォルダを指定する際、「フォルダID」が必要です。
こちらはマイドライブ上で対象フォルダを右クリック、「共有可能なリンクを取得」から取得できます。
今回は件名に「申込書」が含まれ、かつ未読のものだけを検索します。
function attachedFile() {
var search='subject:(申込書) is:unread';
var testOCR = DriveApp.getFolderById('フォルダID');
}
他にも差出人や受信日時など、Gmailの下記検索ウィンドウにある様々な条件で検索することができます。
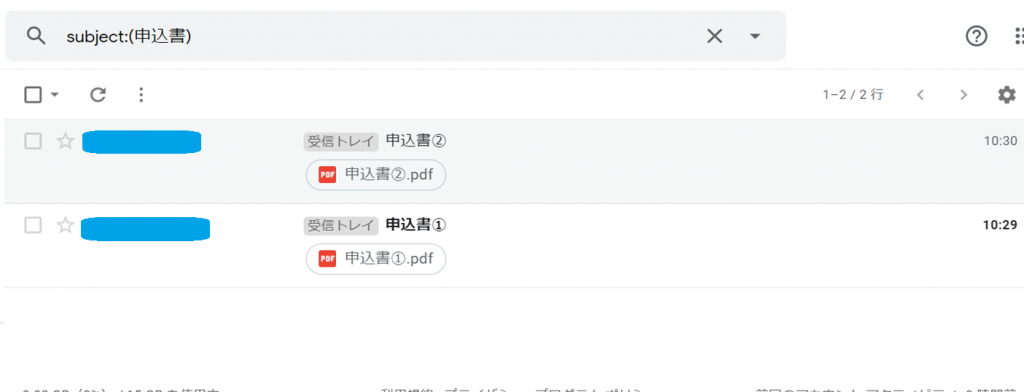
以下の通り件名に「申込書」を含むメールを2通用意しました。
1件は既読なので、申込書①のみ保存されればokです。
//検索条件にマッチしたスレッド取得
var threads=GmailApp.search(search);
//スレッドからメッセージを取得
var messages=GmailApp.getMessagesForThreads(threads);
//取得したメールから添付ファイルを取得
for(var thCnt in messages){
for(var meCnt in messages[thCnt]){
var attachments=messages[thCnt][meCnt].getAttachments();
//ドライブにファイルを保存
for(var fileCnt in attachments){
testOCR.createFile(attachments[fileCnt]);
}
}
}
Gmailでは複数のメッセージがスレッドとしてまとめられているため、
メッセージは[スレッド][メッセージ]の2次元配列で取得します。
以下のようにファイルが保存されました。
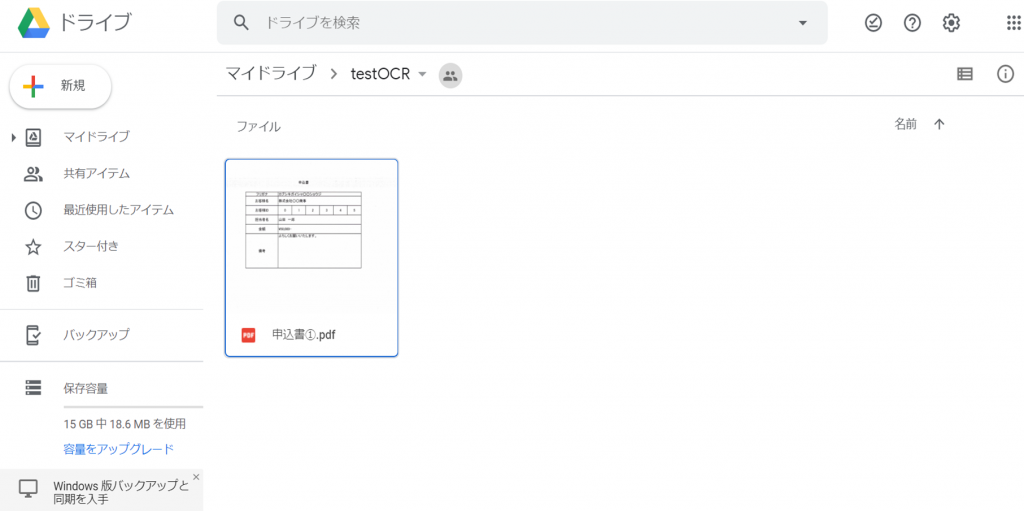
OCRでドキュメントファイルに変換
ドライブに保存することができたら、次はOCR機能を利用しドキュメントファイルへ変換します。
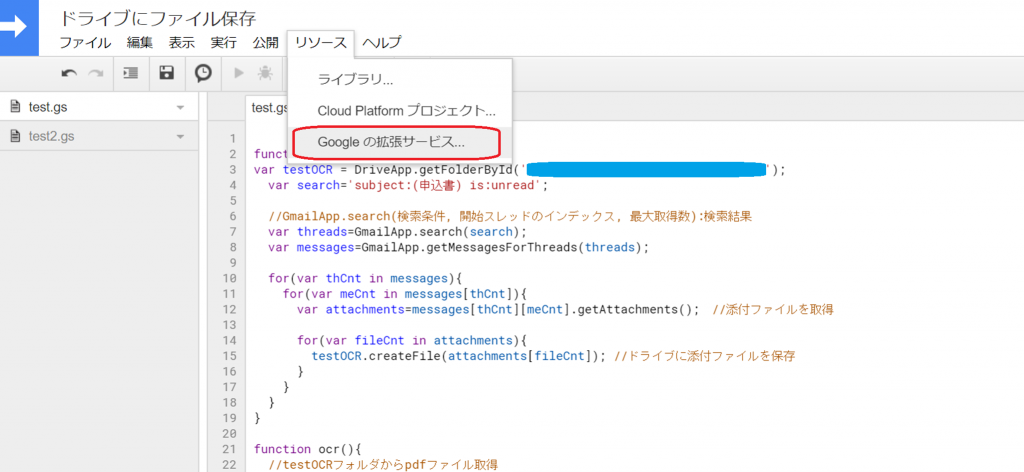
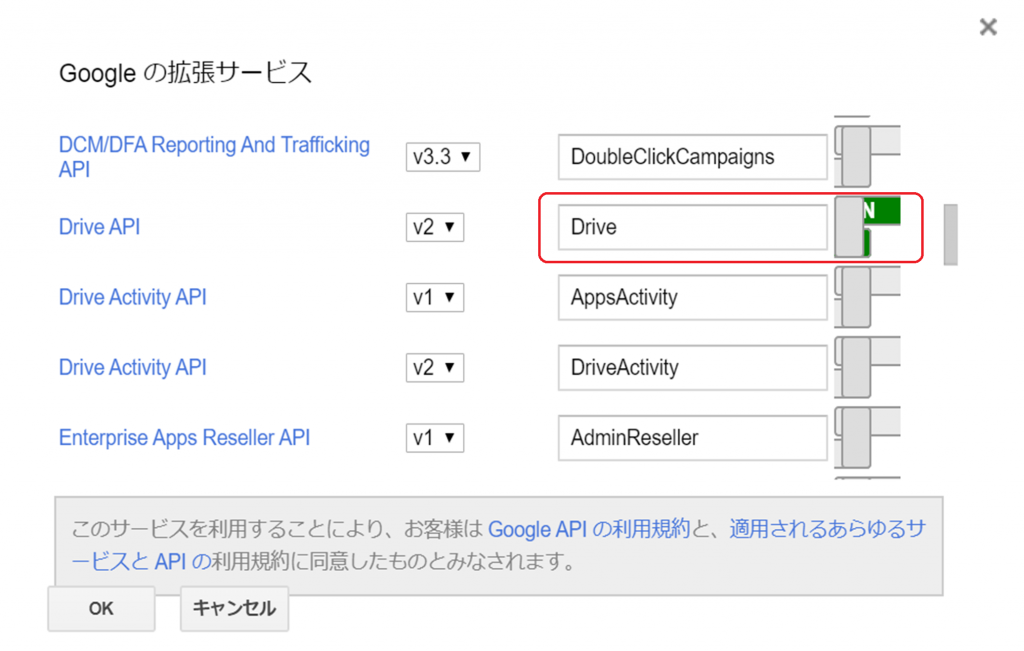
OCR機能を使用するため、まずスクリプトエディタの「リソース」タブより「Google拡張サービス」を選択、DriveAPIを「有効」にします。
testOCRフォルダから対象ファイルを取得、変換前にBlobオブジェクト( Apps Scriptサービスのデータ交換オブジェクト)を取得します。
function ocr(){
//testOCRフォルダからpdfファイル取得
var pdfFiles=testOCR.getFiles();
while(pdfFiles.hasNext()){
var pdfFile=pdfFiles.next();
var fileName=pdfFile.getName();
//作成するドキュメントの情報
var resource={
title: fileName, //ファイル名
mineType: 'pdf' //ファイルタイプ
};
//ファイルからBlobオブジェクト取得
var data=pdfFile.getBlob();
}
}
以下でOCRを有効化し、ドキュメントファイルに変換しています。
ドキュメントファイルはマイドライブ直下に作成されるので、testOCRフォルダへ追加し直下にあるファイルは削除します。
//OCR有効化、ファイルID取得
var fileId = Drive.Files.insert(resource, data, {ocr: true}).id;
var newFile=DriveApp.getFileById(fileId);
//ドキュメントファイルをtestOCRフォルダへ
testOCR.addFile(newFile);
DriveApp.getRootFolder().removeFile(newFile);
文字起こしの精度を確認してみます。

テキストはほぼ正確に取得できたのですが、お客様IDの部分が画像のように複数行にまたがってしまいました。
罫線も文字として捉えられてしまったことや空白が改行と判断されたことが原因なのではと思い、ID記入欄の罫線を削除し他の行と同様の形式に修正し再度試してみました。

以下が変換後のファイルです。
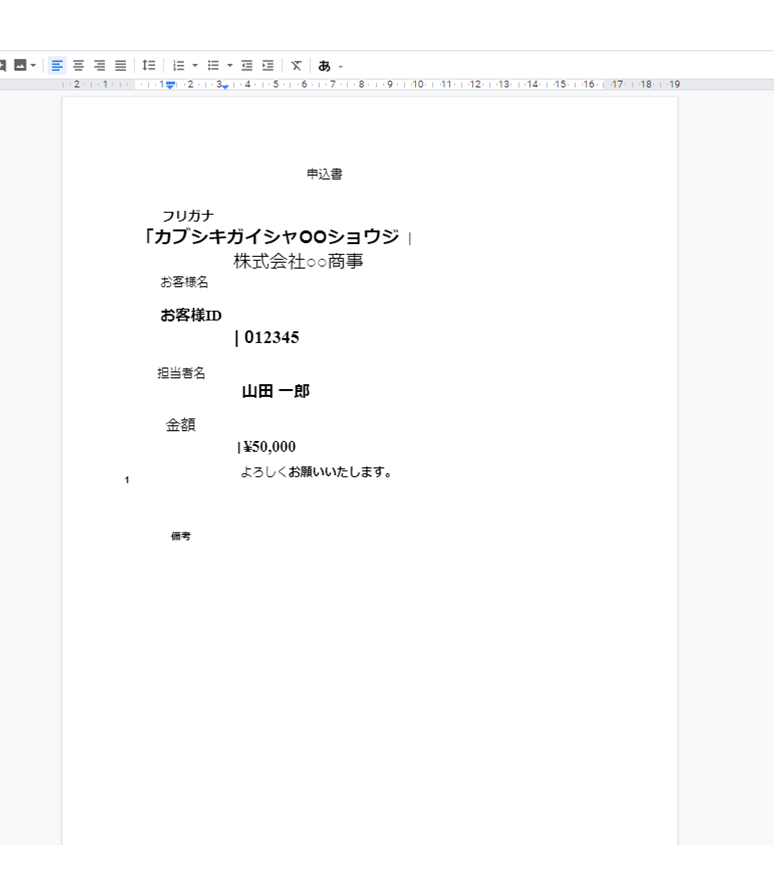
行のずれや記入欄外側の枠線が多少残っていますが、ほぼ解消されました。
スプレッドシートへ転記
作成したドキュメントファイルからテキストデータを取得しスプレッドシートへ転記します。
罫線削除後のドキュメントを使用し、改行区切りで転記するようにしました。
var sheet=SpreadsheetApp.getActiveSheet();
var newFile=DocumentApp.openById(fileId);
//テキストデータ代入
var ocrText = newFile.getBody().getText();
//改行区切りで配列代入
var textArray=ocrText.split('\n');
//スプレッドシートへ入力
for(var arrCnt=0; arrCnt<textArray.length; arrCnt++){
sheet.getRange(arrCnt+1, 1).setValue(textArray[arrCnt]);
}
以下のようにスプレッドシートに入力されました。
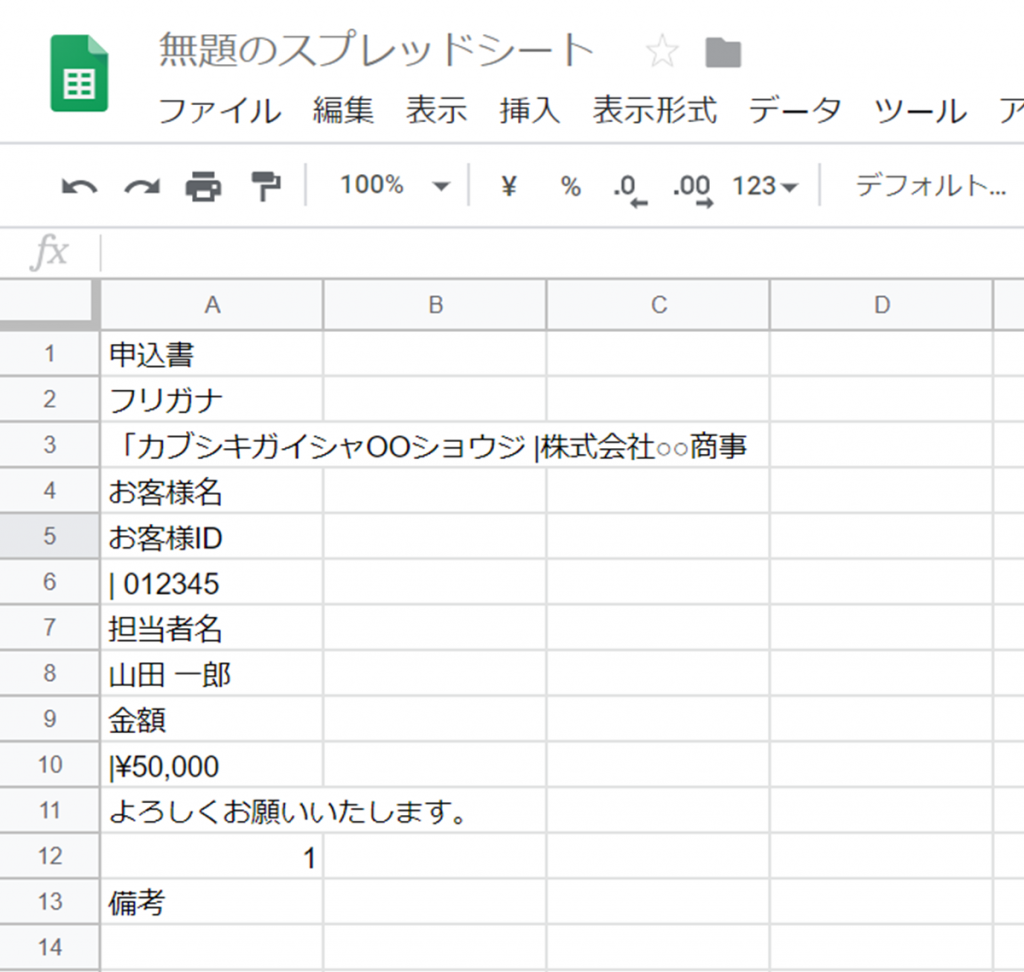
以下がコード全文です。メール取得~添付ファイル自動保存、OCR機能の利用~スプレッドシートへの転記、の2つに分け、ocr_testにて呼び出しています。
function ocr_test(){
attachedFile();
ocr();
}
function attachedFile() {
var search='subject:(申込書) is:unread';
var testOCR = DriveApp.getFolderById('フォルダID');
//検索条件にマッチしたスレッド取得
var threads=GmailApp.search(search);
//スレッドからメッセージを取得
var messages=GmailApp.getMessagesForThreads(threads);
//取得したメールから添付ファイルを取得
for(var thCnt in messages){
for(var meCnt in messages[thCnt]){
var attachments=messages[thCnt][meCnt].getAttachments();
//ドライブにファイルを保存
for(var fileCnt in attachments){
testOCR.createFile(attachments[fileCnt]);
}
}
}
}
function ocr(){
var testOCR = DriveApp.getFolderById('フォルダID');
//testOCRフォルダからpdfファイル取得
var pdfFiles=testOCR.getFiles();
while(pdfFiles.hasNext()){
var pdfFile=pdfFiles.next();
var fileName=pdfFile.getName();
//作成するドキュメントの情報
var resource={
title: fileName, //ファイル名
mineType: 'pdf' //ファイルタイプ
};
//ファイルからBlobオブジェクト取得
var data=pdfFile.getBlob();
//OCR有効化、ファイルID取得
var fileId = Drive.Files.insert(resource, data, {ocr: true}).id;
var newFile=DriveApp.getFileById(fileId);
//ドキュメントファイルをtestOCRフォルダへ
testOCR.addFile(newFile);
DriveApp.getRootFolder().removeFile(newFile);
var sheet=SpreadsheetApp.getActiveSheet();
var newFile=DocumentApp.openById(fileId);
//テキストデータ代入
var ocrText = newFile.getBody().getText();
//改行区切りで配列代入
var textArray=ocrText.split('\n');
//スプレッドシートへ入力
for(var arrCnt=0; arrCnt<textArray.length; arrCnt++){
sheet.getRange(arrCnt+1, 1).setValue(textArray[arrCnt]);
}
}
}
イベントトリガーを設定
最後に、上記作業を定期的に行うためのイベントトリガーを設定します。
スクリプトエディタ画面の「編集」タブより「現在のプロジェクトのトリガー」を選択してください。
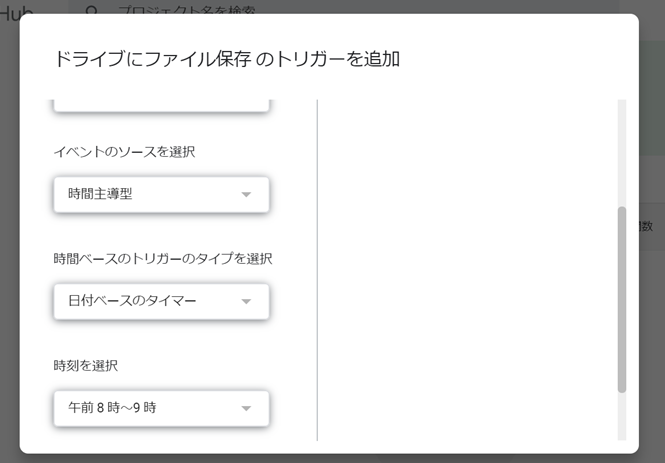
「トリガーを追加」を押下すると以下のような追加画面になりますので、イベントのソースやタイプを選択してください。
今回は毎日朝8時~9時に設定しました。
日付ベースのタイマーを設定すると、実行時間を〇時〇分、と正確に決めることはできず、〇時~〇時といった幅のある設定になります。
この幅の中で1回実行されます。
最後に
始めて触ったGoogleのOCR機能でしたが、日本語・数字をほぼ正確に認識できており、精度の高さを感じました。
ただ罫線や空白の扱い方等にはまだ注意すべき点が多く、利用者側で欲しい情報の形式などを事前に定めておく必要がありそうです。
またテキスト化後のデータの扱い方も工夫が必要だと感じました。
申込書など統一されたフォーマットならばテキスト位置はおそらく似たものになるので、それを利用することでさらに使いやすいデータを作成できるのではないでしょうか。
工夫次第でOCR機能の活用方法が広がることがわかりました。無料で利用することができるので、今後もより便利な方法を探してみようと思います。