
目次
はじめに
前回、機械学習サービスの1つである「Google Cloud Vision API 」についての簡単なご紹介と、
Vision API を使用するための設定等を行いました。
今回は、クライアントライブラリ(Python)をインストールし、コードを実行して画像内のラベルを検出していきたいと思います。
Pythonのインストール
では早速、公式の手順に従ってクライアント ライブラリ(Python)をインストールしていきたいと思います。
コマンドプロンプトを立ち上げ、以下のコマンドを入力します。
pip install --upgrade google-cloud-vision
これで Vision API を使用して画像の情報をリクエストできるようになりました。準備完了になります!
ラベル検出やってみた
それでは、さっそく画像に関連するラベル(単語)を検出させようと思います。
①画像を用意
まずは、こちらの標準的な猫で検証したいと思います。凛々しい猫です。
(標準的な猫、完全に私の主観です・・・)

私のローカル環境は、以下のようなディレクトリ構成にしています。こちらの猫の画像はdataフォルダ配下に配置しました。
ai_test_2022/
├ data/
│ └ cat
└ test1
②コーディング
それでは、test1.py に Python でコードを書いていきます。サンプルソースコードが公式のページに載っていますので、それを自分の環境に合わせて微修正します。
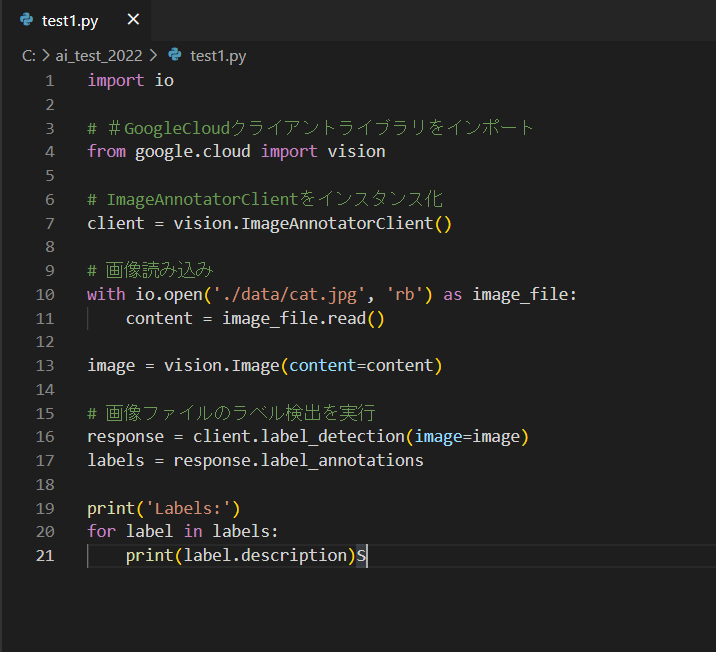
このコードを見ていくと、「ImageAnnotatorClient」というクラスを使用しています。
公式ページを参照しますと、顔、ランドマーク、ロゴ、ラベル、テキスト検出など、クライアント画像に対してGoogle CloudVisionAPI検出タスクを実行するもののようです。
※ 前回も少し触れましたが、「アノテーション」とは、画像、テキスト、音声、動画など様々な対象に対する「ラベルづけ」のことです。機械学習においては教師データを作る上で欠かせないものになります。
また、コードに「label_detection」 とありますが、こちらも公式ページを参照しますと、以下のように説明があります。
リクエストが成功すると、サーバーはレスポンスを JSON 形式で返します。LABEL_DETECTION レスポンスには、検出されたラベル、スコア、トピカリティ、不透明ラベル ID が含まれます。
| 項目名 | 内容 |
|---|---|
| mid | 存在する場合は、このエンティティの Google Knowledge Graph エントリに対応する MID(Machine-generated Identifier)が格納されます。 |
| description | ラベルの説明 |
| score | 信頼スコア。0(信頼できない)から 1(信頼度が非常に高い)の範囲で示されます。 |
| topicality | 画像に対する ICA(Image Content Annotation)ラベルの関連度。 ページの全体的なコンテキストに対するラベルの重要度 / 関連度を測定します。 |
それでは、どういった結果が表示されるか、Pythonを実行してみます。
結果
①猫
コマンドプロンプトを開き、「C:\ai_test_2022\code」のディレクトリで、以下のコマンドを実行します。
python test1.py
すると、
Labels: Head Cat Eye Felidae Carnivore Window Small to medium-sized cats Whiskers Snout Terrestrial animal
こんな感じでラベルが表示されました。窓・・・?!
これだけだとラベルごとの信頼度がよく分かりませんので、
先ほどの LABEL_DETECTION の項目の「score(信頼スコア)」も表示させるようにしようと思います。
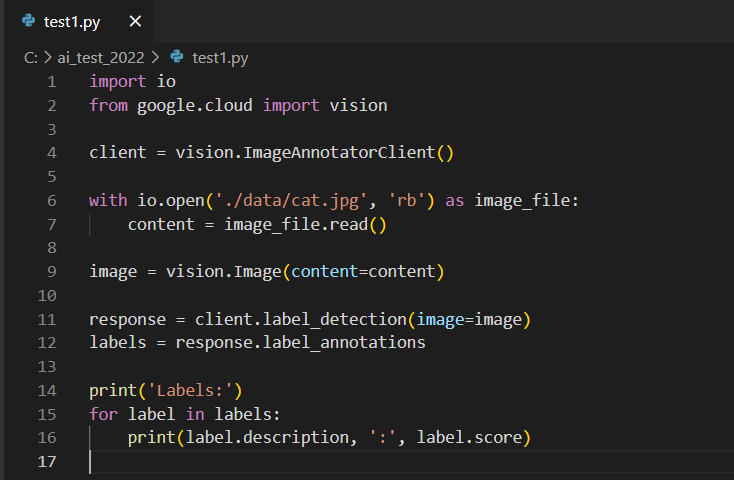
「label.score」を追記して、再度コマンドを実行します。
Labels: Head : 0.9724438786506653 Cat : 0.9499096274375916 Eye : 0.9413082003593445 Felidae : 0.9108079671859741 Carnivore : 0.9009854793548584 Window : 0.8666111826896667 Small to medium-sized cats : 0.8550629615783691 Whiskers : 0.837993323802948 Snout : 0.7689116597175598 Terrestrial animal : 0.7306946516036987
猫の頭であるということはしっかり判定されたみたいです。窓の信頼スコアは86%というなかなか衝撃です。
この猫は窓にも見えるのですね。面白いです。
猫単体で検証してみましたが、公式のサンプル画像を見る限り情報量が多いものの方が良さそうなので、
次は風景の画像で検証してみようと思います。
②神戸市街
身近な場所の画像にしてみました!こちらは神戸の旧居留地の街並みです。

コードを実行すると・・・
Labels: Daytime : 0.9449639347543012 Plant : 0.91240783869672301 Building : 0.9059518428573618 Road surface : 0.8938178224254723 Infrastructure : 0.8926476254931465 Tree : 0.8509724431022829 Urban design : 0.8439324512785221 Neighbourhood : 0.84277351225065779 Window : 0.8308643807676993 Sidewalk : 0.8130733120821403
この画像は夜ですが、明度を判断して「 Daytime 」がラベルとして検出されているのですね~。
「 Plant 」「 Building 」「 Road surface 」「 Tree 」「 Window 」「 Sidewalk 」など、的確に画像内の情報を言語化してくれています。
③ゴッホ「星月夜」
次に、絵の場合はどのように表示されるのか気になりましたので、検証してみたいと思います。

コードを実行すると・・・
Labels: Paint : 0.9022921919822693 Nature : 0.8995094299316406 Azure : 0.8969144225120544 Painting : 0.8764228224754333 Textile : 0.8721943497657776 Vegetation : 0.8497583270072937 Art : 0.8485283851623535 Tree : 0.8345407843589783 Grass : 0.8320682644844055 Sky : 0.8287011981010437
「Paint」だと認識されています!この画像の質感から読み取ったのでしょうか。
今回のように分かりやすい絵画だとこのように認識されるのですね。
もう少し具体的なラベルは検出できないか気になったので、検証してみたいと思います。
④エリンギ
キノコ類は様々種類がありますが、キノコと一括りにされず「エリンギ」と判定されるのでしょうか。

コードを実行すると・・・
Labels: Fawn : 0.8150516748428345 Wood : 0.7822701930999756 Beige : 0.6253003478050232 Mushroom : 0.6122145652770996 Plant : 0.563472330570221 Natural material : 0.5484763383865356 Metal : 0.5299309492111206 Fashion accessory : 0.5243878960609436 Still life photography : 0.5126955509185791 Ingredient : 0.5060304999351501
「 Mushroom 」で一括りにされていますね。具合的な単語の検出は不可能なのでしょうか。
⑤バラ
もう少し見た目が分かりやすいもので検証してみます。「花」と一括りにされず「バラ」のラベルは検出されるのでしょうか。

コードを実行すると・・・
Labels: Flower : 0.9811161756515503 Plant : 0.9586992859840393 Petal : 0.9024657607078552 Hybrid tea rose : 0.8716349005699158 Rose : 0.8099624514579773 Garden roses : 0.7800278663635254 Flowering plant : 0.7686492204666138 Rose family : 0.7467091679573059 Rose order : 0.7344076633453369 Floribunda : 0.7274734377861023
「Rose」として認識されているようです!そのうえ「Hybrid tea rose」というラベルまでも検出されています。
事前に定義されてあるもの/ないものの線引きは難しそうですね。
終わりに
今回のように「Google Cloud Vision API」を使用することで、機械学習の教師データを作成せずとも簡単に画像認識を行うことができます。風景の画像などから簡易な情報を取得するのには十分適しているように思います。
一方で 、事前定義済みカテゴリにはないラベルの検出はできず、定義されてあるもの/ないものの線引きも難しいため、より具体的な情報が知りたいのであれば他の方法で行うのがよさそうです。
独自の画像認識を実現できるよう、今後は機械学習モデルを自分で作成してみたいと思いました。
調べてみた中で、「Google Cloud AutoML Vision」 を使って機械学習モデルの作成を行う方法もあるそうなので、折を見てやってみたいと思います!



