
目次
前回のおさらい
前回は、ビッグデータ蓄積・利用時の課題を考え、以下の対応する方法を挙げました。
- インデックスチューニング
- パーティション分割
- データ圧縮
上記に対応することで、ビッグデータを取扱う際の主にレスポンスを改善することに有効と考えました。
今回はデータパーティショニングについて記述していこうと思います。
データパーティショニングとは
データパーティショニングでビッグデータの課題に対応すると言いましたが、そもそもデータパーティショニングとはどのようなものなのか。

データベースをパーティション(分割)するとは、データベース自体を分割し、分散データベースとすることや、データベース内のテーブルだけを分割することを指します。
複数のデータベースを作成し、分割する方法は、リンクサーバ(Oracle,PostgreSQLではデータベースリンクと呼ばれる)の機能を利用することで実現できます。
しかし、導入時に複数のDBに分割しておくとよいですが、途中で分割するとなると既存のクエリの改造が発生し、改造規模が大きくなります。
データベース内のテーブルを分割する方法は、ある範囲のデータごとにデータの格納先を変更する方法です。言葉だけを見ると、範囲ごとのテーブルを新規作成し、データごとに範囲から格納先を分岐させるようなイメージが浮かぶかも知れませんが、それに限らず、SQLServerにはパーティショニング機能が存在し、論理的なテーブルを作成して自動的に格納データファイルを切り替えることが出来ます。
格納データファイルを切り替えることによって、アクセスするデータベースファイルが異なるため、ファイルI/Oを分散し、パフォーマンス改善が望めます。
このパーティショニング機能は、SQLServer2014まではEnterprize Editionのみの機能だったのですが、SQLServer2016 SP1にてEdition間での機能差が緩和され、その他のEditionでも使用できるようになりました。

今回は、テーブル分割をSQLServerのパーティショニング機能で実施してみます。
データパーティショニング
データパーティショニングを行う準備として、まずは分割の方法と分割範囲を決めます。
分割方法としては、期間ごとに水平分割(行分割)し、分割範囲は年毎にパーティションを作成します。
工場毎には分割せず、工場の指定はインデックスによってパフォーマンズ向上を図ります。しかし、複数工場の同時参照をしない(工場単位で管理するため、別工場とは関係性がない等)、工場ごとにテーブルを分けているほうが管理がし易いなどといった条件が或る場合には、工場毎にテーブルを作成し、さらに期間ごとにパーティショニングするといった方法も有効的だと思われます。
分割範囲については月毎で分割してもよいのかもしれませんが、データ参照をする際に当年のデータはアクセスが多いと考えられることや、月毎の分割数ではデータファイルが多くなり管理が煩雑になる恐れがあるため、今回はデータ格納テーブルを年毎に水平分割(行で範囲分割)したいと思います。
データパーティショニングは、SQLで行ってもよいのですが、今回はSQLServer Management StudioにてGUIで設定していきます。
ファイルグループの作成
まずはSQL Server Management Studio(以下、SSMSとする)を起動し、データベースにログインします。
指定のデータベースを選択し、コンテキストメニューからプロパティを開きます
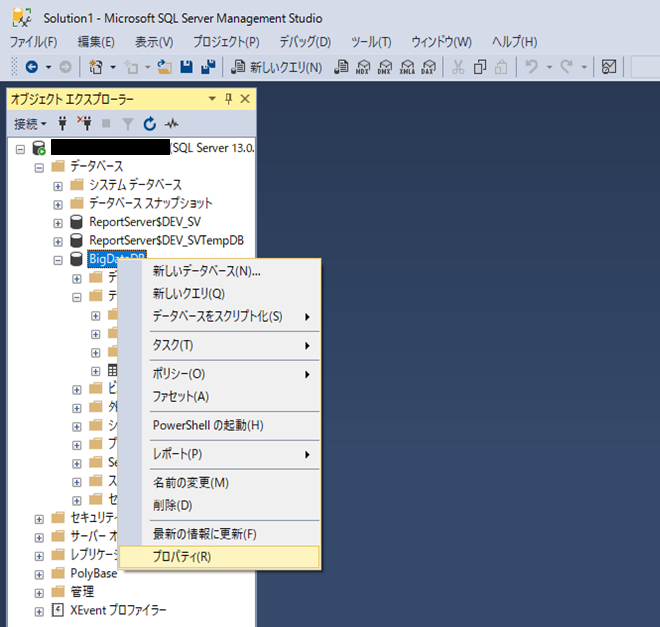
プロパティ画面のファイルグループから、ファイルグループの追加をクリックします。
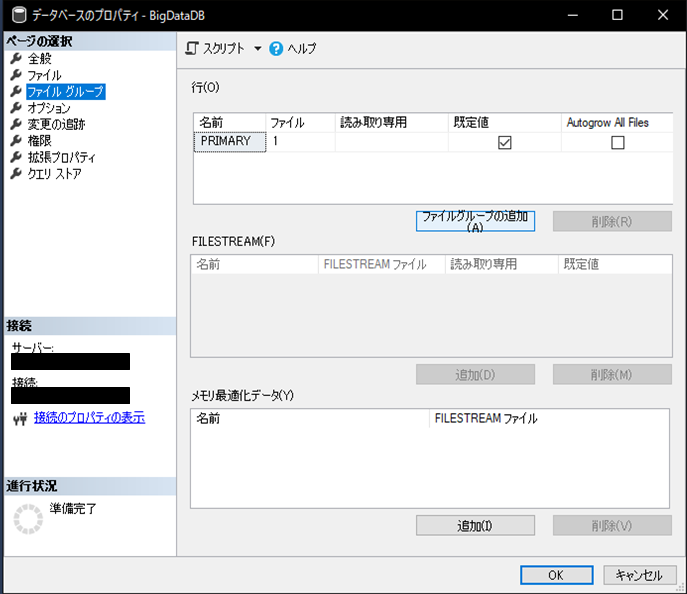
必要な分割数の分だけ、ファイルグループを追加します。今回は2018年~2020年を年毎に分割します。
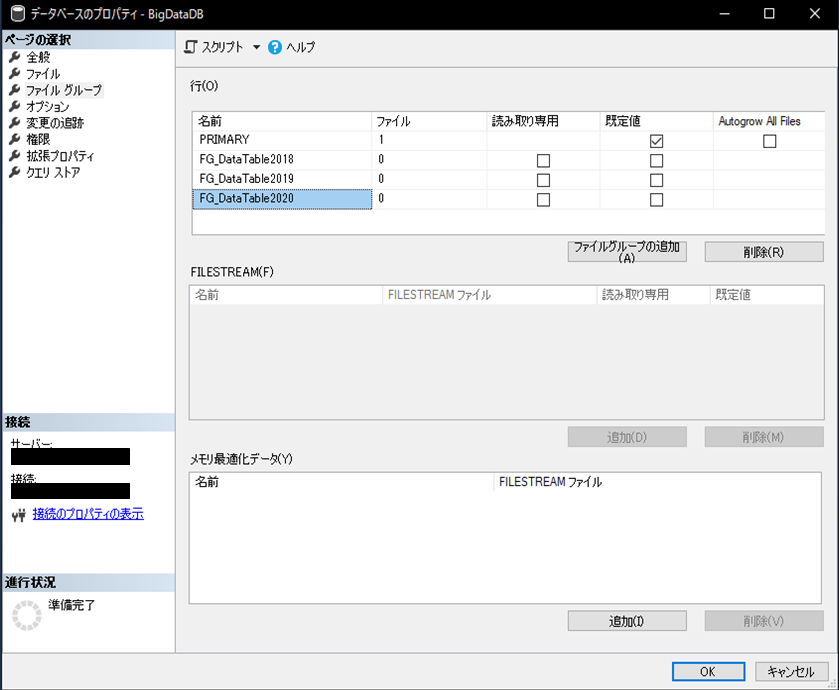
ファイルグループを作成後、左側のメニューからファイルを選択し、ファイルグループごとに実際のデータファイルを作成し、それぞれのファイルグループに属するように設定します。
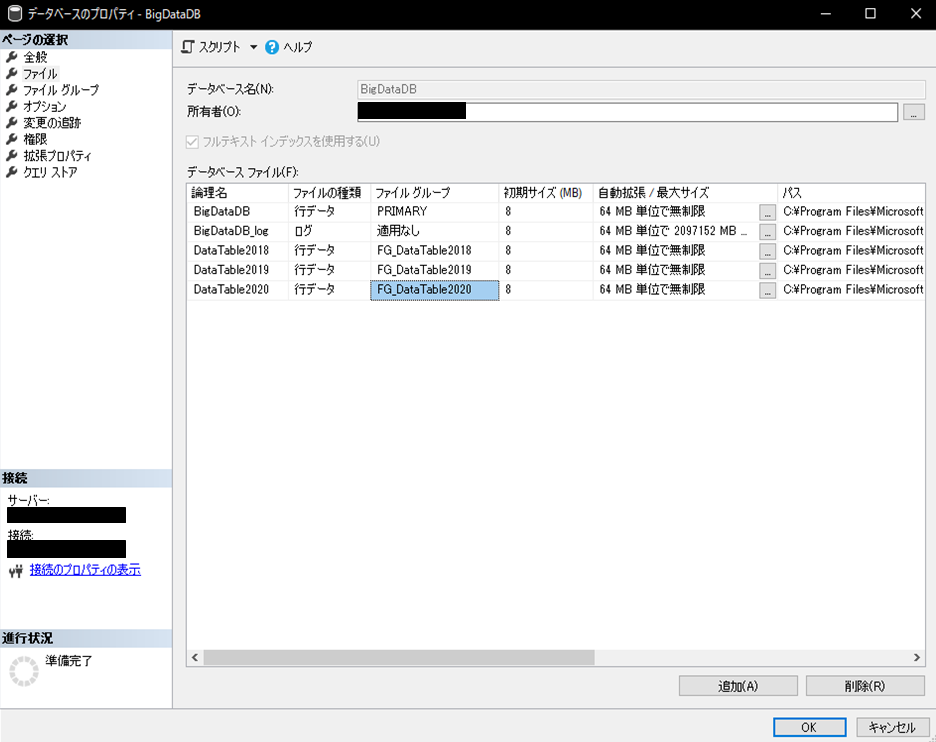
これでパーティション分割する準備が出来ました。
パーティションの作成ウィザードによるパーティションの作成
パーティション分割をしたいテーブルを右クリックし、ストレージ→パーティションの作成を選択します。
パーティションの作成ウィザードが表示されるのでOKボタンをクリックします。
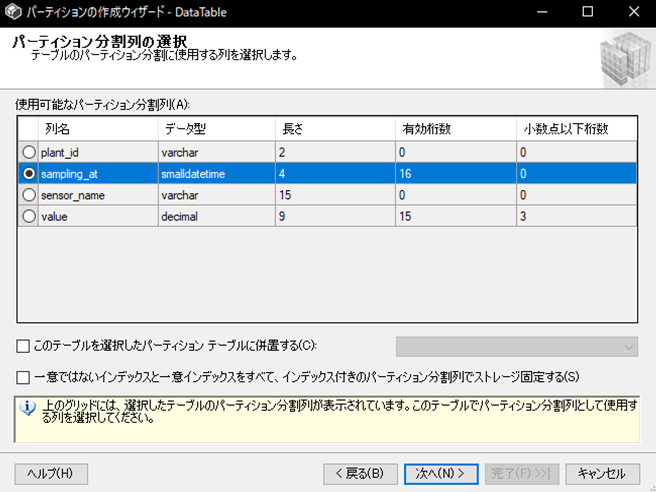
パーティション分割列の選択
まずはパーティションの分割する基準のデータ列を選択します。
今回は年毎に分割したいので、収集日時(sampling_at)列を選択します。
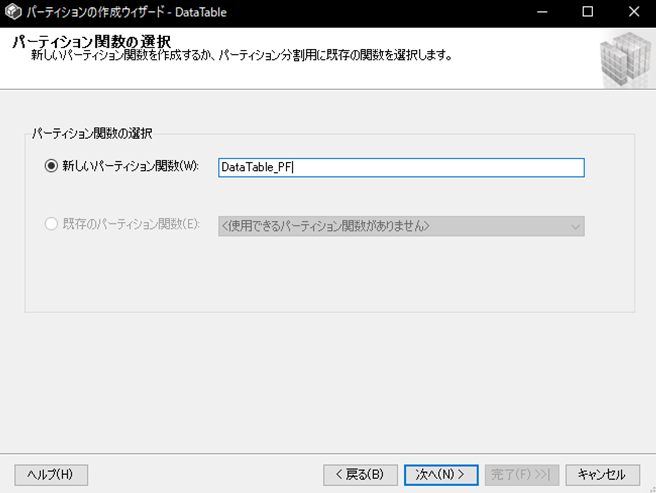
パーティション関数の選択
パーティション関数の名前を決めます。任意の名前でよいですが、パーティション関数であることがわかるほうがよいと思います。
パーティション関数の内容は、後で設定する境界値の設定で自動的に作成されます。
パーティション構成の選択
パーティション構成の名前を決定します。こちらも任意の名前でよいですが、パーティション構成とわかる名前がよいと思います。
パーティションのマップおよび境界値の設定
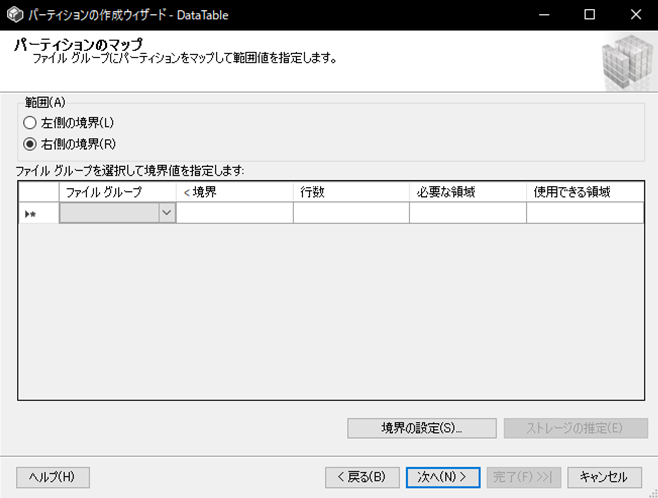
パーティションをどのように分割するか境界値を設定します。
範囲は、「左側の境界」と「右側の境界」とありますが、境界値をどちらに含めるかの設定となります。
左側の境界であれば境界値の「≦(以下)」のデータをパーティションに含めます。右側の境界であれば「<(未満)」のデータをパーティションに含めます。今回の場合は年毎に分割するため、境界値には各年の1/1を設定するので右側の境界を選択します
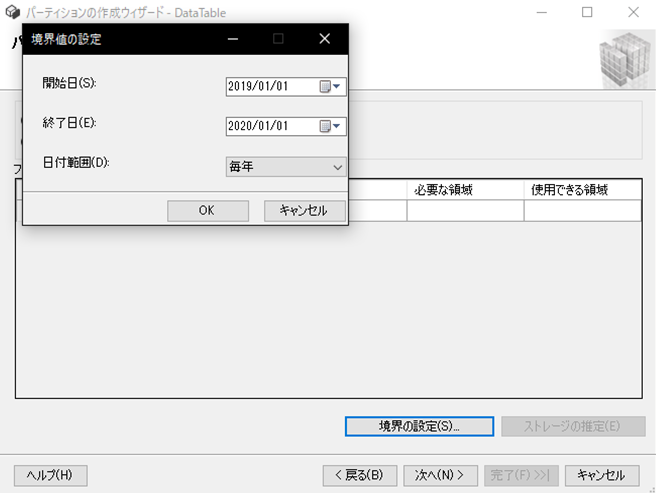
また、多量に分割する場合は一つ一つ作成すると手間がかかりますが、 多量の分割を設定する補助ツールが備わっています。境界の設定ボタンをクリックすると、境界値の設定ダイアログが表示されるので、期間と分割単位を設定します。
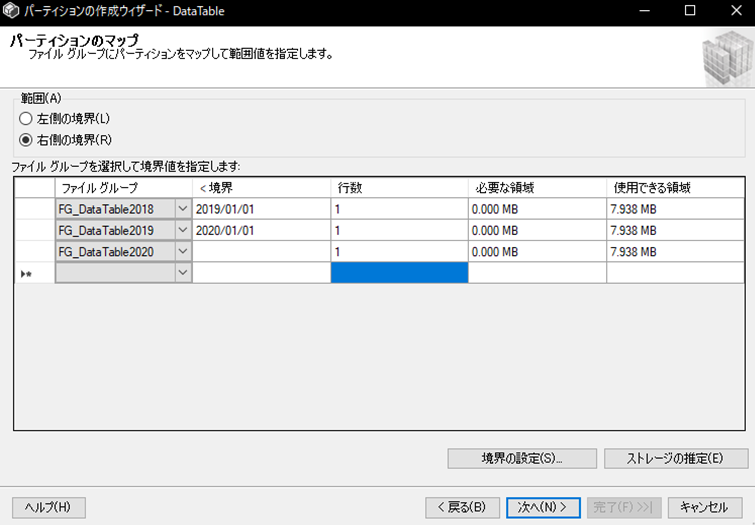
分割を設定後、ファイルグループを紐づけます。一番下のファイルグループには「2020/1/1」以降のデータが格納されていきます。
実行
スクリプトを作成するか、すぐに実行するかを選択します。
今回はすぐに実行します。
確認画面が表示され、よければOKボタンをクリックします。
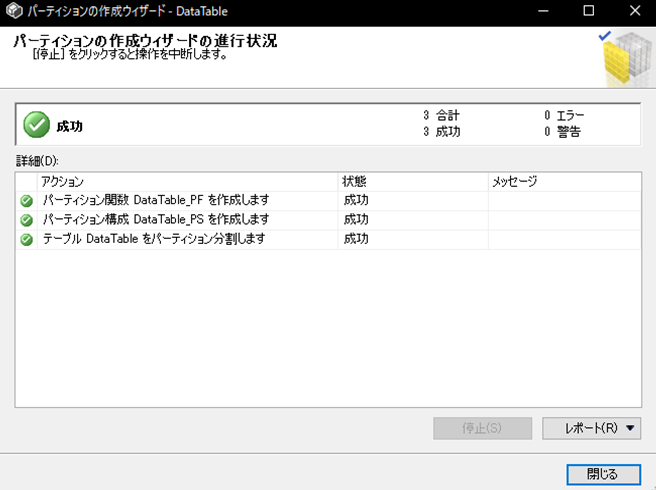
すべて正常に成功すればパーティション分割が完了しました。
パーティションの確認
実際にデータ挿入後、下記SQLを実行すると、データごとにどのパーティションに格納されたが確認できます。
SELECT
[パーティション番号] = $partition.DataTable_PF([sampling_at]),
*
FROM
DataTable
これでテーブルのパーティション分割は完了です。
データパーティショニングは、既に多量のデータが格納されている場合には、インデックスの更新が発生するため長時間の処理を必要とし、Enterprise Editionでなければシステムへの影響を考慮しなければならないため注意が必要です。
他RDBでのデータパーティショニング機能
SQLServer以外のRDBにもパーティショニング機能があるか調査してみたところ、Oracle、MySQL、PostgreSQLにもパーティショニングをする機能があります。
コマンドではどのRDBでも出来るのですが、各RDBの代表的なクライアントソフトではパーティション操作をGUIで出来るかも調査したところ以下のような状況でした。
| RDB | SQLServer | Oracle | MySQL | PostgreSQL |
| クライアントソフト | SSMS | SQLDeveloper | phpMyAdmin | pgAdmin |
| GUIでのパーティショニング | 〇 | 〇 | △ | 〇 |
| 備考 | – | – | パーティションの削除は出来るが追加は出来ない | PostgreSQL11でパーティショニングの改善予定 |
おわりに
今回はデータパーティショニングについて記述してみました。
データパーティショニングは、データI/Oの分散だけでなく、データの部分削除、部分的な圧縮など分割した単位で操作ができ、操作時の影響を小さくできるなどメリットが多く、SQLServer2016 SP1からすべてのEditionで使用可能となったので改善案のひとつとして積極的に利用しやすくなっています。
次回は、データ圧縮について記載していこうと思います。本テーマは次回で終了予定です。





