
目次
前回のおさらい
データ圧縮とは
データ圧縮
他RDBでのデータ圧縮機能
おわりに
前回のおさらい
前回までに、ビッグデータ蓄積・利用時の課題の対応策として以下の方法を挙げ、インデックスチューニング、パーティション分割について記述しました。
- インデックスチューニング
- パーティション分割
- データ圧縮
今回は、最終回ということでデータ圧縮について記述していこうと思います。
データ圧縮とは
データ圧縮は、データの余分な空白部を切り捨てたり、未使用のページを削除するなどでデータ量を削減する機能です。

データ圧縮をすると、データ量が小さくなるだけでなく、データの密度が大きくなり、取得するページ数を抑えることが出来ます。ページ数を抑えることで、データI/Oを小さくできることや、圧縮されたままメモリ上にキャッシュされるためパフォーマンスの向上に繋がることがあります。
ただし、データ圧縮をしているため、圧縮されたデータを利用する際には圧縮・解凍プロセスが実行され、CPUのリソースを使用するので場合によってはパフォーマンスが下がってしまうことがあるので注意が必要です。
上記のデメリットがあるため、データ圧縮は使用頻度の低いデータに対して部分的にデータ圧縮を実行することでこのデメリットを回避することが出来ます。部分的にデータ圧縮をするために、前回記述したデータパーティショニング機能を利用します。
データパーティショニングで分割したファイルごとにデータ圧縮を実行することが出来ます。
データ圧縮には以下の2通りの方法があります。
- 行圧縮
- ページ圧縮
行圧縮は、数値型を可変長に変更することや空白文字を除外することによって、データ圧縮を行います。ページ圧縮は、上記の行圧縮に加え、プレフィックスの圧縮やディクショナリの圧縮も実行することでデータ圧縮を行います。
圧縮時にはインデックスの再構築が伴うため、格納されているデータが多いほどストレージの空き容量が十分に必要なことと処理に時間が必要となります。
データ圧縮
データ圧縮を実施する際に、以下のストアドを実行すると圧縮による削減量の見積りが行えます。
exec sp_estimate_data_compression_savings
@schema_name = 'BigDataDB' ,
@object_name = 'DataTable' ,
@index_id = NULL , --インデックスのid。すべてのインデックスの場合はNULLを指定
@partition_number = NULL , --パーティションNo。すべてのパーティションの場合はNULLを指定
@data_compression = 'ROW'; --行圧縮の場合は[ROW]、ページ圧縮の場合は[PAGE]を指定
データ圧縮は、SQLでも行えますが、SQLServer Management StudioにてGUIで設定していきます。
対象テーブルの選択
圧縮対象のテーブルを右クリックし、圧縮の管理を選択します。
データ圧縮ウィザードによるデータ圧縮
データ圧縮ウィザードが表示され、簡単に圧縮作業を行えます。
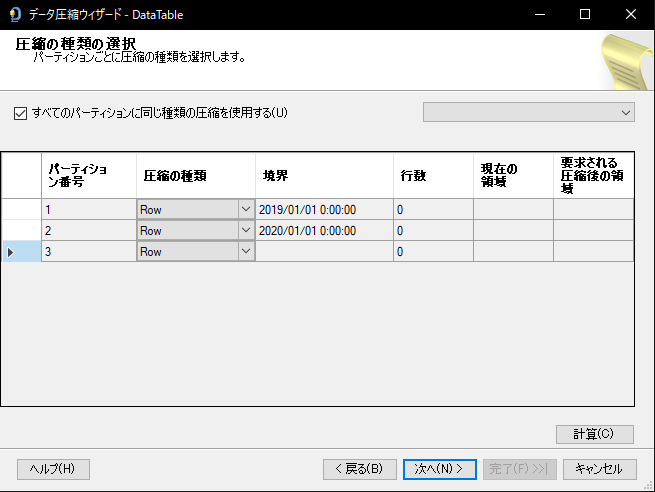
圧縮の種類の選択
パーティション毎に圧縮の種類を行圧縮(Row)かページ圧縮(Page)か選択できます。
実行
あとは圧縮を実行するだけです。スケジュールを設定して、自動的に実行することもできます。
他RDBでのデータ圧縮機能
SQLServer以外のRDBにもデータ圧縮機能があるか調査してみたところ、Oracle、MySQLにもデータ圧縮機能がありました。
Oracleでは表圧縮機能と呼ばれ、SQLServerとは異なり、重複値を排除することでデータ圧縮を図っています。
MySQLには通常のデータ圧縮機能に加え、透過性データ圧縮というMySQL(InnoDB)による圧縮/展開処理と、OSのファイルシステム側の機能を組み合わせて実現する圧縮機能があります。
おわりに
5 回の連載でオンプレミスRDBでのビッグデータと表して記載しましたが、ビッグデータをオンプレミスで取り扱うとハード面での拡張が容易には行えないため、容量の確保やデータ量の削減、既存の処理速度でデータ量が増加してきたときのレスポンスを維持する等、事前に適切な方策がとられていればよいが、実際はどうしても継ぎ接ぎのような対策を講じなければいけないことがあります。
ビッグデータはその特性上、データの急速な増加による頻繁な領域拡張、CPUの強化など、クラウドの最も得意とするところではありますが、企業や扱うデータによってはオンプレ下でやらざるを得ない場合が少なからず発生します。その際、少しでも効率よく資源を活用できるようこのようなテクニックが活用出来ればと思い、この連載を続けてまいりました。他の連載でクラウドでのデータベース活用についての記事も掲載しておりますので、ご覧いただけたらと思います。https://itport.cloud/?tag=season1





