
目次
はじめに
今回やりたいこと
失敗SQL:Excel的な考え方
Accessでの処理手順
正解SQL:GROUP BY と INNER JOIN の併用
おわりに
はじめに
ログやマスタなどのデータを扱う際、これまでずっとExcelを使ってきたのですが、大きなデータだと止まってしまうことが多く、最近Accessを使って作業することが増えてきました。
Accessを使う中で、Excelに慣れているがゆえに行き詰まったことがあったので、記事にまとめてみます。
今回やりたいこと
今回私が詰まったのが、「特定のフィールドのみ重複を除外する」という作業です。
さらに条件として「最大のレコードを優先して重複除外」したい、という処理でした。
たとえば、とある会社のホームページを、複数名の社員で日々更新しているとします。
操作ログとして、誰がいつ、どのページを編集したかが出力された「t_logdata」というテーブルがあります。
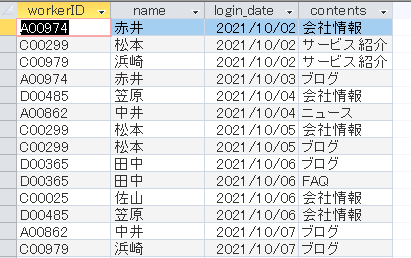
このログから、「各コンテンツを一番最後に編集したのは誰か」を調べます。
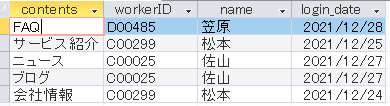
つまり、「contents」を「login_date」が最大のレコードで一意にしたいという作業です。
最終的にはこんな結果が得られるのが望ましいです。
失敗SQL:Excel的な考え方
Excelを使い慣れていると、この場合の処理は「「login_date」を降順に並べ替えて「contents」列の重複削除」という流れがまず頭に浮かぶのではないかと思います。
それをそのままSQLっぽく書こうとすると、こういうものを想定してしまうのではないでしょうか。
SELECT DISTINCT contents,
workerID,
name,
login_date FROM t_logdata
ORDER BY login_date desc;
結果はこうなります。
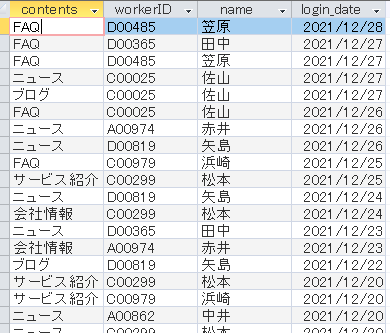
重複だらけです。…それはそうですよね。
上記のSQLはあえて分かりにくい改行にしていますが、
「DISTINCT」は「contents,workerID,name, login_date」全体にかかっているわけで、
Excelで処理するときのように「contents」のみの重複削除にはなっていないのです。
Excelの「並べ替えて重複削除」という操作は、最初のデータが優先されるという設定のもとで成り立っているのですが、Accessはこのあたりを明確に指定する必要があります。
「この条件の下で特定されたこのデータを返す」という考え方です。
この例で言えば、「contents」カラムのみ重複削除しようとしても、各「contents」に対して複数の「workerID」「name」「login_date」が対応し得るため、Access側はどのデータを返せばいいのか判断できません。
「一つのカラムのみにDISTINCTを適用して、その行のレコード全体を取得する」という考え方では、Accessでは処理できないのです。
Accessでの処理手順
ではAccessで「最大のレコードを優先して特定のフィールドの重複を除外」という処理はどう考えるか。
これはAccessに限らずですが、データベースからSQLでこのような処理を行う場合は、「フィールドでグループ化し、各グループの中の最大のレコードを取得する」という考え方になるようです。
ここで調べたいのは「各コンテンツを最後に編集したのは誰か」なので、「contents」のフィールドでグループ化して、各コンテンツの最新の日付(=最大の日付)の行を取得します。
正解SQL:GROUP BY と INNER JOIN の併用
他のやり方もあったのですが、こちらの記事のやり方が速く処理できたので使わせていただきました。
「contents」ごとにグループ化して最大日付を取得したテーブルを作成し、元のテーブルとJOINする、という方法です。
SELECT DISTINCT
logA.contents,
logA.workerID,
logA.name,
logA.login_date FROM t_logdata AS logA
INNER JOIN (SELECT
contents,
max(login_date) AS maxdate
FROM t_logdata GROUP BY contents) AS logB
ON logA.contents = logB.contents
AND logA.login_date = logB.maxdate;
実行結果はこちら↓
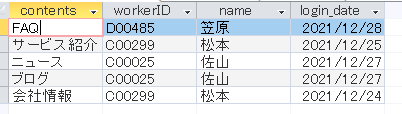
希望通りの結果になりました。
上記のSQLがどのような処理になるかというと、
SELECT DISTINCT
logA.contents,
logA.workerID,
logA.name,
logA.login_date FROM t_logdata AS logA
⇒まずは最終的に表示させたい列を記述しています。(「DISTINCT」にしているのは、「同じ日に同じ人が同じコンテンツを編集した」という場合のレコード重複を削除するためです。)
元のテーブルを、今後扱いやすいように一旦「logA」という名前にしておいています。
INNER JOIN (SELECT
contents,
max(login_date) AS maxdate
FROM t_logdata GROUP BY contents) AS logB
⇒その「logA」に、同じく「t_logdata」から「コンテンツごとにグループ化して、最終日付を出したテーブル」(※)を内部結合します。
このあとのデータの扱いやすさのために、このテーブルを「logB」、「max(login_date)」を「maxdate」と置いています。
(※)上記のサブクエリの、
SELECT contents,max(login_date) AS maxdate
FROM t_logdata GROUP BY contents
のみを実行すると下記のようなテーブルになっています。(=「logB」)
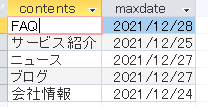
各コンテンツの最終編集日付が取得できています。これを元テーブルに内部結合します。
INNER JOINなので、このテーブル(logB)と元のテーブル(logA)のどちらにも存在する分のみが結合されます。
ON logA.contents = logB.contents
AND logA.login_date = logB.maxdate;
⇒結合条件を2つ記述しています。
「contents」が一致するだけでなく、「logA」の方の「login_date」が「logB」の「maxdate」と一致しているもののみを抽出します。
ちなみに「結合なんて面倒くさいことをせずに、「contents」でグループ化したあとに「contents,workerID,name,max(login_date)」を全て持ってきてしまえばよいのでは」と考えがちなのですが、
Accessでは、グループ化した中に入っていない情報は取ってくることができません。
SELECTのあとに指定した項目は、すべてGROUP BY句もしくは集計関数の引数に指定されなければならないという規定があります。(詳細はこちら)
この例でいえば、「contents」でグループ化しているのでcontentsは取得可能、login_dateの最大値も集計関数(max)で取得できますが、「workerID」および「name」は該当しません。
おわりに
一見同じようなテーブルを扱っているように見えても、同様の結果を得るための作業プロセスは、ExcelとAccessでは異なります。扱うデータの特性に合わせて使い分けたいところです。
たとえば今回のように、データ量が少ないシンプルな作業であれば、Excelの方が直感的に手っ取り早く操作できる印象です。
一方、大きなデータを扱う場合、複数のテーブルを扱う必要がある場合などは、Accessの方が作業に適しています。
(ただしAccessにも2GBの容量制限があります。詳細はこちら)
双方の使い方を理解し、適材適所で効率よくデータ処理を行えるようにしていきたいと思います。





