
目次
前回の振り返り
機械学習法
サポートベクターマシンとは
学習モデルへの実装
前回の振り返り
機械学習法
学習モデル作成にあたり、目的や使用するデータによって使用する機械学習の手法が異なってきます。
前回作成した学習モデルでは教師あり学習と呼ばれる中のサポートベクターマシンという手法を使用しました。
教師あり学習とは、物の特徴などのデータと正解となるラベルが存在するデータとの結びつきの法則を学習させる手法であり、データ分類に使用されています。
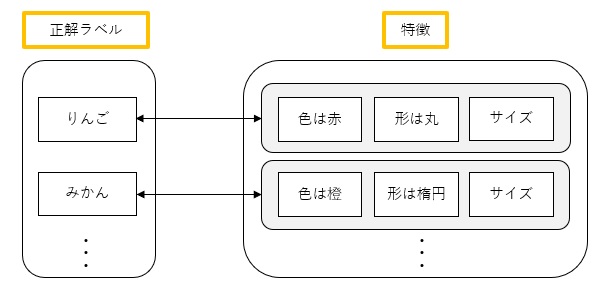
身近なものだと手書き文字の認証やカメラの画像認識は正解となる画像データから機械学習を行わせた学習モデルです。
逆に正解ラベル無しで学習させる手法は教師なし学習と呼ばれます。
こちらはデータ分析や予測に使用されています。
身近なものだとショッピングサイトのおすすめ出力は、ユーザの購入・商品の閲覧記録から学習モデルが予測結果を出力したものです。
サポートベクターマシンとは
サポートベクターマシンとはパターン識別の手法の一つで、形や色などの特徴データのグループの範囲に対し、境界線を引いてデータを分類します。
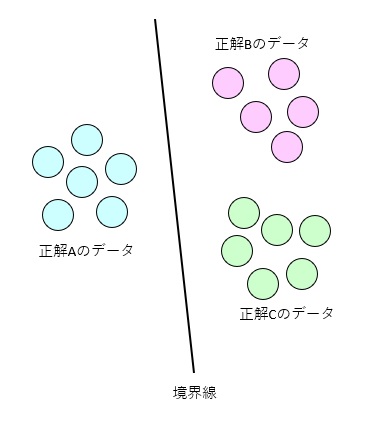
境界線から各データの範囲までの距離を大きくする事でデータ分類時の特徴の誤差の許容範囲が広がり、柔軟性を持たせる事ができるのがサポートベクターマシンの特徴です。
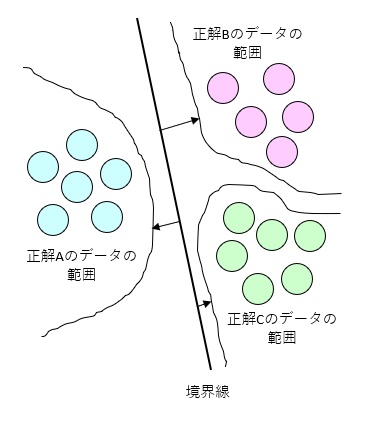
学習モデルへの実装
前回紹介した学習モデルではAnaconda環境にてPythonを使用して学習モデルを作成しました。
Anacondaのインストーラは下記よりダウンロードできます。
https://www.anaconda.com/download
Pythonのscikit-learn(機械学習用のライブラリ)にはサポートベクターマシンを実装するライブラリ関数が用意されているため、手軽に機械学習を実装できます。
SVCメソッド※で誤差をどの程度許容するかの重み付けを行い、fitメソッド※で特徴データと正解ラベルの関係性の学習を行っています。
from sklearn import svm # 機械学習に使う
from sklearn.externals import joblib # 学習モデルファイルの入力・出力に使う
#-------------------------------------------------------------------------
# 中略
#-------------------------------------------------------------------------
# サポートベクターマシン(SVM)による機械学習
clf = svm.SVC(gamma = 0.1, C=100) # SVMの設定。gamma・Cは境界線を決める重み(バイアス値)
clf.fit(test_x, label_i) # 機械学習。test_x:特徴データの配列 label_i:正解ラベルの配列
# 学習モデルの外部出力
joblib.dump(clf,'test_learn_model.pkl',compress=True)
特徴データとして色・形・幅・高さを配列にしていますが、fitメソッドは数値しか扱えないので色と形はそれぞれ数値の配列に変換しています。
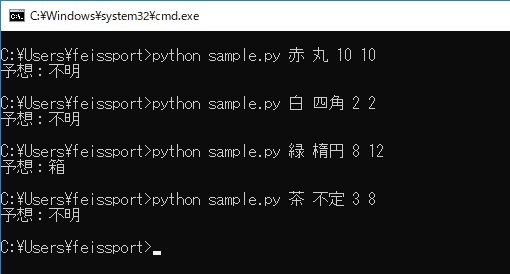
重み付けを変えると以下のように出力結果が変わります。
gammaはデータ範囲ごとの境界線をどれだけ複雑にするか、Cは誤分類をどれだけ許容するかを表します。
gamma = 0.1, C=100
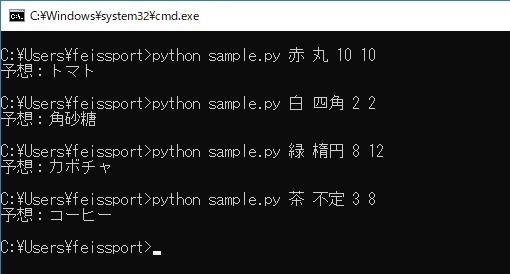
gamma = 0.001, C=100
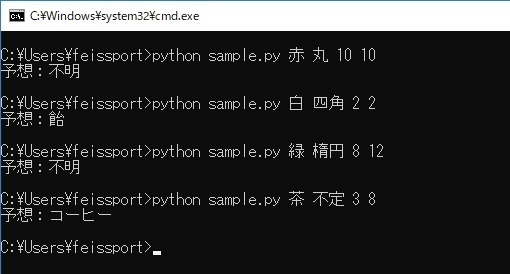
gamma = 1.0, C=100
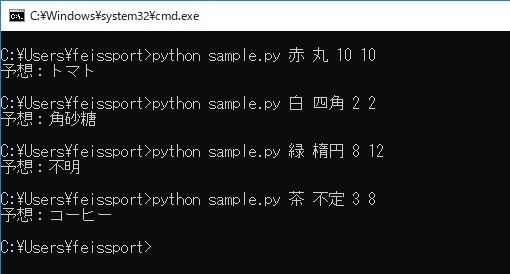
gamma = 0.1, C=1
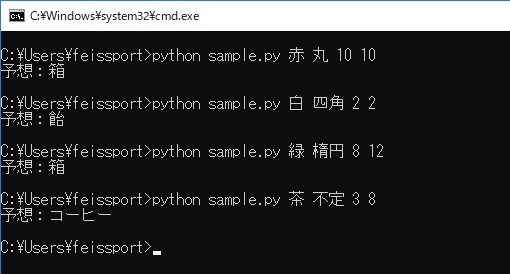
gamma = 0.1, C=0.15
実際は数点のチェックでは望んだ出力が行われるかは分からず、何パターンも入力を試したり、重みを調整したり、別のデータを与えて学習を繰り返すなどの調整を行う必要があります。
次回はAnaconda環境のインストールやプログラムの実行方法に触れていきたいと思います。
※本記事に記載した用語は別記事にてご紹介したいと思います



