はじめに
Amazon QuickSightは、データの分析・可視化・ワークフローの自動化・組織全体での コラボレーションを実現する、生成AIを活用したBIツールです。
主な構成要素として「データセット」「分析」「ダッシュボード」の3つがあります。
SQLを使わなくても画面からの操作でデータをテーブルなどに可視化することができます。
ですが、ダッシュボードの数が増えてくると、以下のことが大変になってきます。
- 開発・検証・本番のように環境やアカウントが分かれていて、毎回画面から手作業で同じ内容を作り直すのが辛い
- 環境間で設定にズレが生じてしまう
この記事では、Terraformを使ってQuickSightのデータセットをコードで管理する方法を紹介します。
また、Quicksight上でもデータセットのSQLは履歴管理されていますが、
作成したSQLファイルをGitで管理することで環境間の展開が可能になり、変更履歴の追跡・チームでの共同作業も可能になります。
Terraformとは
Terraformはインフラをコードで管理するツールです。
通常、AWSのリソース(今回はQuickSightのデータセットなど)はコンソール画面でポチポチ作成しますが、Terraformを使うと .tf ファイルを通じて自動で作成・更新・削除できます。
tfファイルを書く → terraform plan(差分確認)→ terraform apply(実際に反映)
構成の概要
今回作成するフォルダ構成は以下のとおりです。
(社内用の想定のため、.gitignoreは作成しておりません。用途に合わせて設定ください。)
quicksight-iac/
├── environments/
│ ├── dev/
│ │ └── main.tf # 開発環境の設定
│ ├── stag/
│ │ └── main.tf # 検証環境の設定
│ └── prod/
│ └── main.tf # 本番環境の設定
└── modules/
└── dataset/
├── main.tf # データセットのリソース定義
├── variables.tf # 変数定義
├── outputs.tf # 出力定義
└── sql/
└── *.sql.tftpl # SQLファイル(環境変数対応)
ポイント:SQLのテンプレート変数
環境ごとにデータベース名だけが異なる場合、SQLファイルに変数としてデータベース名を埋め込むことで、1つのSQLファイルを全環境で使い回せます。
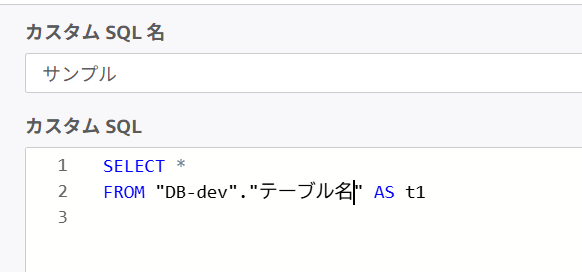
-- 環境変数を使ったSQLの例
SELECT *
FROM "${database_name}"."テーブル名" AS t1${database_name} の部分が環境ごとに自動で置き換わります。
| 環境 | データベース名(仮で設定しました) |
|---|---|
| 開発 | DB-dev |
| 検証 | DB-stag |
| 本番 | DB-prod |
今回のデータソースはAWS Athena(S3上のデータをSQLで検索できるサービス)です。
QuickSightからAthenaに接続する設定(データソース)は事前に手動で作成済みの前提で進めます。
セットアップ手順
1. AWS CLIのインストールと設定
AWS CLIインストーラー をダウンロードして実行します。
インストール後、PowerShellで認証情報を設定します。
aws configure以下を順番に入力します。
AWS Access Key ID: (IAMユーザーのアクセスキーID)
AWS Secret Access Key: (シークレットアクセスキー:IAMから発行)
Default region name: ap-northeast-1
Default output format: json接続確認:
aws sts get-caller-identityアカウント情報が表示されればセットアップ完了です。
2. Terraformのインストール
今回は以下のサイトを参考にさせていただきました。
windowsにTerraformをインストールする
https://qiita.com/watyanabe164/items/99bd119e23c5ed9b71ac
3. フォルダ作成
今回使用するフォルダをそれぞれコマンドプロンプトから作成します。
mkdir quicksight-iac
cd quicksight-iac
mkdir environments\dev
mkdir environments\stag
mkdir environments\prod
mkdir modules\dataset
mkdir modules\dataset\sqlファイルの中身
modules/dataset/variables.tf
このファイルはモジュールが受け取る変数の定義です。環境ごとに異なる値(アカウントID・DB名など)をここで宣言しておくことで、呼び出し側から値を渡せるようになります。
variable "aws_account_id" {
description = "AWSアカウントID"
type = string
}
variable "database_name" {
description = "Athenaのデータベース名"
type = string
}
variable "dataset_id" {
description = "QuickSightデータセットID"
type = string
}
variable "dataset_name" {
description = "QuickSightデータセット名"
type = string
}
variable "data_source_arn" {
description = "QuickSightデータソースのARN"
type = string
}
variable "quicksight_user_arn" {
description = "QuickSightユーザーのARN"
type = string
}
modules/dataset/main.tf
このファイルがQuickSightのデータセットを作成する本体です。
直接クエリを使用するのでimport_modeで”DIRECT_QUERY”としています。
SPICEを使用する場合、”SPICE”としてください。
resource "aws_quicksight_data_set" "this" {
data_set_id = var.dataset_id
name = var.dataset_name
import_mode = "DIRECT_QUERY"
physical_table_map {
physical_table_map_id = "primary"
custom_sql {
data_source_arn = var.data_source_arn
name = var.dataset_name
sql_query = templatefile("${path.module}/sql/${var.dataset_id}.sql.tftpl", {
database_name = var.database_name
})
columns {
name = "placeholder"
type = "STRING"
}
}
}
permissions {
actions = [
"quicksight:DescribeDataSet",
"quicksight:DescribeDataSetPermissions",
"quicksight:PassDataSet",
"quicksight:DescribeIngestion",
"quicksight:ListIngestions",
"quicksight:UpdateDataSet",
"quicksight:DeleteDataSet",
"quicksight:CreateIngestion",
"quicksight:CancelIngestion",
"quicksight:UpdateDataSetPermissions",
]
principal = var.quicksight_user_arn
}
}
modules/dataset/outputs.tf
このファイルはモジュールが外部に返す値の定義です。
output "data_set_arn" {
description = "データセットのARN"
value = aws_quicksight_data_set.this.arn
}
environments/dev/main.tf
このファイルが開発環境の設定です。
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 5.0"
}
}
}
provider "aws" {
region = "ap-northeast-1"
}
# 環境ごとに変わる値をまとめて定義(ここを変えるだけで別環境に対応できる)
locals {
aws_account_id = "(開発アカウントID)"
database_name = "DB-dev"
quicksight_user_arn = "arn:aws:quicksight:ap-northeast-1:(開発アカウントID):user/default/(ユーザー名)"
data_source_arn = "arn:aws:quicksight:ap-northeast-1:(開発アカウントID):datasource/(データソースID)"
}
# 作成したいデータセット分だけ追加していく
module "dataset_sample" {
source = "../../modules/dataset"
aws_account_id = local.aws_account_id
database_name = local.database_name
dataset_id = "sample"
dataset_name = "サンプルデータセット"
data_source_arn = local.data_source_arn
quicksight_user_arn = local.quicksight_user_arn
}modules/dataset/sql/(データセット名).sql.tftpl
通常のSQLとほぼ同じ書き方です。
DB名の部分だけ "${database_name}" に置き換えるだけで、あとは普通にSQLを書けます。
作成したい分だけファイルを作成が必要です。
SELECT
*
FROM "${database_name}"."(テーブル名)" AS t1
データセットを作成する
初期化
cd quicksight-iac\environments\dev
terraform init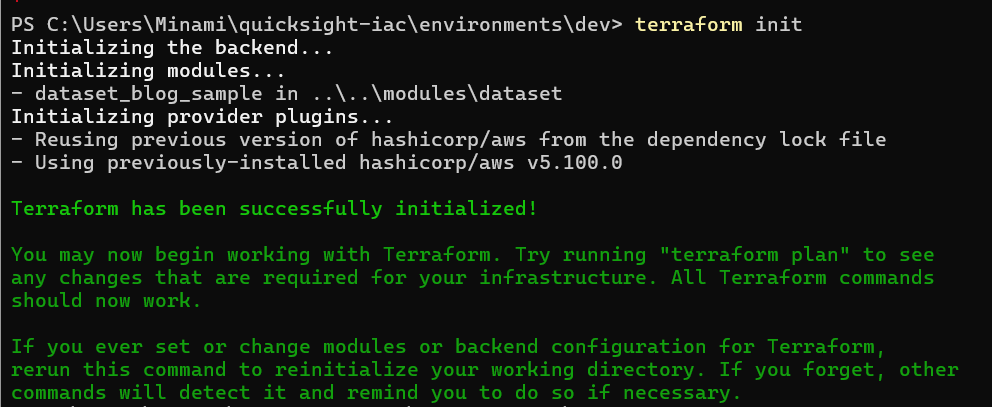
差分確認(AWSには何も変わりません)
terraform plan今回は追加になります。

作成・変更・削除される内容が表示されます。問題なければ次へ。
実際に反映
terraform apply
yes を入力すると実際にQuickSightにデータセットが作成されます。
SQLを更新する場合
SQLファイルを編集して terraform apply を実行するだけです。Terraformが差分を検知して既存のデータセットを更新します。
データセットを追加する
新しいデータセットを追加するときは:
modules\dataset\sql\に新しい.sql.tftplファイルを追加environments\dev\main.tfにmoduleブロックを追加
module "dataset_new" {
source = "../../modules/dataset"
aws_account_id = local.aws_account_id
database_name = local.database_name
dataset_id = "new_dataset" # SQLファイル名と一致させる
dataset_name = "新しいデータセット"
data_source_arn = local.data_source_arn
quicksight_user_arn = local.quicksight_user_arn
}
dataset_id とSQLファイル名(.sql.tftpl の前の部分)を必ず一致させてください。
検証・本番環境への展開
environments\(環境)\main.tf の database_name を検証環境のDB名に変えるだけです。
locals {
database_name = # ここだけ変える
...
}
あとは同じSQLファイルが使われます。
まとめ
Terraformを使うことで以下が実現できました。
- SQLの変更履歴をGitで管理できる
- 1つのSQLファイルで複数環境に展開できる
terraform applyだけでデータセットを作成・更新できる