目次
はじめに
ChatGPTやClaudeなどのLLM(大規模言語モデル)は、インターネット上の公開データをもとに学習しています。そのため、自社の規程やマニュアル、議事録など、社内に蓄積された情報については基本的に把握していません。
つまり、生成AIは「自社特有の知識」を持っていないという課題があります。
この課題を解決する代表的な手法が、RAG(Retrieval-Augmented Generation)です。
本記事では、RAGの概要や処理の流れ、導入メリット、活用シーンについてわかりやすく解説します。
LLM単体の限界
LLMの知識は学習時点の情報に基づいているため、社内固有の情報(製品コード、独自フロー、最新の規程など)は含まれていません。
また、分からない内容についても、それらしく誤った回答を生成してしまう「ハルシネーション」が発生する可能性があり、業務利用における大きなリスクとなっています。
RAGは、LLMそのものを再学習・改修することなく、これらの課題に対応できる仕組みです。
RAGとは何か
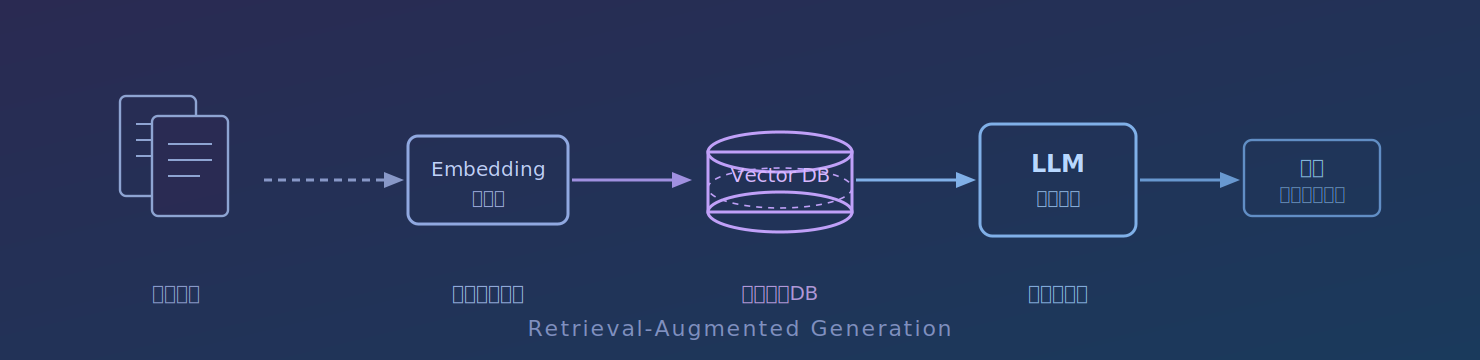
RAGとは、Retrieval-Augmented Generation(検索拡張生成)の略称です。
LLMが回答を生成する前に、外部データベースから関連情報を検索・取得し、その内容をプロンプトへ追加することで、回答精度を向上させる仕組みです。
これにより、社内マニュアルや規程、議事録などを参照した、根拠のある回答や出典付きの応答が可能になります。
また、LLM自体を再学習させることなく、社内知識を活用できる点も大きな特徴です。
処理の流れ
RAGの処理は大きく「事前準備フェーズ」と「回答生成フェーズ」の2段階で構成されます。
── 事前準備フェーズ ──
① ドキュメントの分割(チャンキング)
PDFや社内Wikiなどの文書を、AIが処理しやすい単位(数百〜数千文字程度)に分割します。チャンクが大きすぎると無関係な情報が混入し、小さすぎると文脈が失われるため、文書の構造に合わせた粒度の調整が必要です。
② ベクトル化(エンベディング)
分割した各チャンクをAIモデルで高次元ベクトルに変換します。これにより、テキストの「意味」が数値で表現され、表記が異なっていても意味が近い言葉(例:「規程」と「ポリシー」)を同一の近さとして扱えるようになります。
③ ベクトルDBへの格納
変換されたベクトルを専用のベクトルデータベース(Chroma・Qdrant・pgvectorなど)に保存します。この段階で社内文書の「検索可能な状態」が整います。
── 回答生成フェーズ ──
④ クエリのベクトル化
ユーザーが入力した質問文を、事前準備と同じモデルでベクトルに変換します。
⑤ 類似文書の検索(Retrieval)
質問のベクトルとDBに格納された文書ベクトルを比較し、意味的に近い上位3〜5件を取得します。キーワードが一致しなくても意味が近ければヒットする点が、従来の全文検索との大きな違いです。
⑥ プロンプトへの組み込みと回答生成
取得した文書をコンテキストとしてLLMに渡し、回答を生成します。根拠となる文書が明示されるため、出典の確認も可能になります。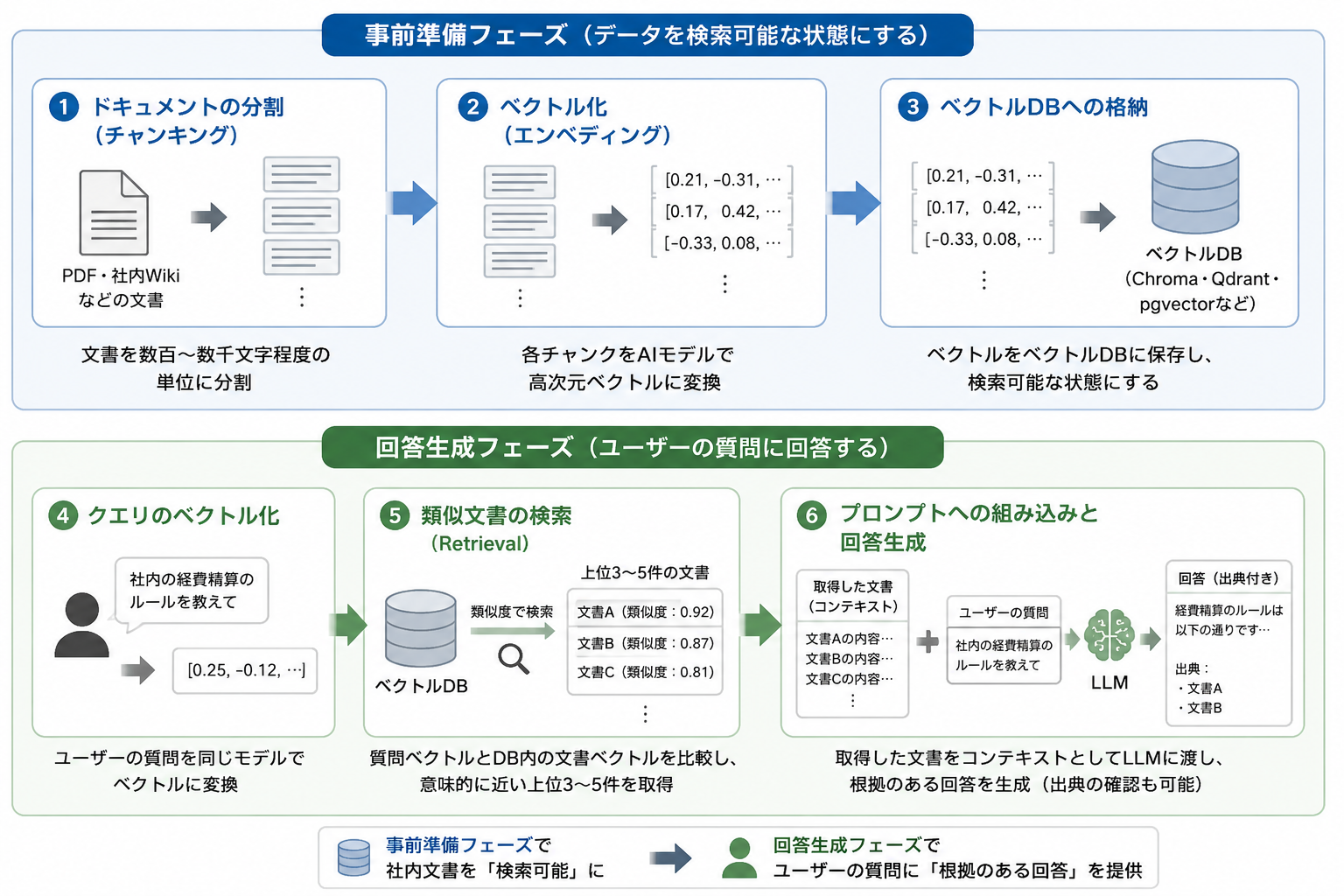
RAGの3つの優位性
①回答精度の向上
具体的な情報源を参照しながら回答を生成するため、ハルシネーションが減少します。Data.Worldの研究ではSQLベースのLLMと比較して精度が3倍以上向上し、LinkedInの事例でも回答品質が77.6%改善したと報告されています。
②データ理解と洞察力の強化
分散した構造化・非構造化データを「知識ネットワーク」として整理し、情報間の潜在的な関係を可視化します。シーメンス・エナジーでは、タービン部品の欠陥とサプライチェーンリスクをリアルタイムで特定し、数千時間の作業削減を実現した事例があります。
③検証可能性とデータセキュリティ
各回答が参照元の文書・DBに対応づけられており、出典の追跡・検証が可能です。ノード単位のアクセス制御設計により、社内データのセキュリティを維持しながら活用できます。
社内での活用シーン
社内規程・業務マニュアルの検索
「この申請には誰の承認が必要か」「経費の上限はいくらか」といった問いに、最新の規程集やマニュアルを参照しながら回答できます。企業規模が大きくなるほど社内文書の数も増え、目的のドキュメントを探すだけで時間がかかりがちです。RAGを活用したチャットボット形式の社内検索により、特に新入社員や異動直後のメンバーが情報を自己解決できる環境を整備できます。
カスタマーサポートの対応補助
製品仕様・FAQ・過去の問い合わせ対応事例などをRAGに組み込むことで、定型的な顧客対応をAIに委ねることができます。オペレーターはイレギュラーな対応に集中できるため、慢性的な人手不足が課題となっているコールセンター・コンタクトセンターの負荷軽減に有効です。
社内ヘルプデスクの自動化
システム操作マニュアルやトラブルシューティング資料をRAGに登録しておくことで、「この画面でエラーが出た場合は?」「パスワードの変更手順は?」といった定型的な問い合わせをAIが代行できます。ヘルプデスク担当者の対応件数を削減し、より高度な案件への対応リソースを確保できます。
まとめ
RAGは、LLMが抱える「知識の固定化」「社内情報への非対応」「ハルシネーション」といった課題に対し、モデル自体を再学習・改修することなく対応できる手法です。
外部データベースから関連情報を検索・取得し、その内容をプロンプトへ組み込むというシンプルな仕組みでありながら、社内文書検索、カスタマーサポート、ヘルプデスクなど、さまざまな業務への活用が進んでいます。
一方で、RAG導入において重要なのは、単なる技術選定ではなく「どの文書を登録するか」という情報設計です。登録文書の品質が低ければ、RAGを導入しても回答精度は向上しません。古い情報や、重複・矛盾した文書が混在しないよう、ドキュメント整備と継続的な管理が前提となります。
また、社内データを扱う以上、アクセス制御やセキュリティ設計も欠かせません。誰がどの情報へアクセスできるかを適切に管理しなければ、権限外の情報が回答に含まれるリスクもあります。
RAGの導入は、単なるAI活用ではなく、社内の情報資産を整理・活用するための取り組みとも言えます。
まずは対象文書を限定した小規模な検証から始め、精度・運用・セキュリティの3つを並行して改善していくアプローチが現実的でしょう。